
Russell Sparse - Sparse matrix tools and solvers
This crate is part of Russell - Rust Scientific Library
Contents
- Introduction
- Installation
- Setting Cargo.toml
- Examples
- Tools
- MUMPS + OpenBLAS issue
- Benchmarks
- For developers
Introduction
This crate implements tools for handling sparse matrices and functions to solve large sparse systems using the best libraries out there, such as UMFPACK (recommended) and MUMPS (for very large systems). Optionally, you may want to use the Intel DSS solver.
We have three storage formats for sparse matrices:
- COO: COOrdinates matrix, also known as a sparse triplet.
- CSC: Compressed Sparse Column matrix
- CSR: Compressed Sparse Row matrix
Additionally, to unify the handling of the above sparse matrix data structures, we have:
- SparseMatrix: Either a COO, CSC, or CSR matrix
The COO matrix is the best when we need to update the values of the matrix because it has easy access to the triples (i, j, aij). For instance, the repetitive access is the primary use case for codes based on the finite element method (FEM) for approximating partial differential equations. Moreover, the COO matrix allows storing duplicate entries; for example, the triple (0, 0, 123.0) can be stored as two triples (0, 0, 100.0) and (0, 0, 23.0). Again, this is the primary need for FEM codes because of the so-called assembly process where elements add to the same positions in the "global stiffness" matrix. Nonetheless, the duplicate entries must be summed up at some stage for the linear solver (e.g., MUMPS, UMFPACK, and Intel DSS). These linear solvers also use the more memory-efficient storage formats CSC and CSR. See the russell_sparse documentation for further information.
This library also provides functions to read and write Matrix Market files containing (huge) sparse matrices that can be used in performance benchmarking or other studies. The [read_matrix_market()] function reads a Matrix Market file and returns a [CooMatrix]. To write a Matrix Market file, we can use the function [write_matrix_market()], which takes a [SparseMatrix] and, thus, automatically convert COO to CSC or COO to CSR, also performing the sum of duplicates. The write_matrix_market also writes an SMAT file (almost like the Matrix Market format) without the header and with zero-based indices. The SMAT file can be given to the fantastic Vismatrix tool to visualize the sparse matrix structure and values interactively; see the example below.
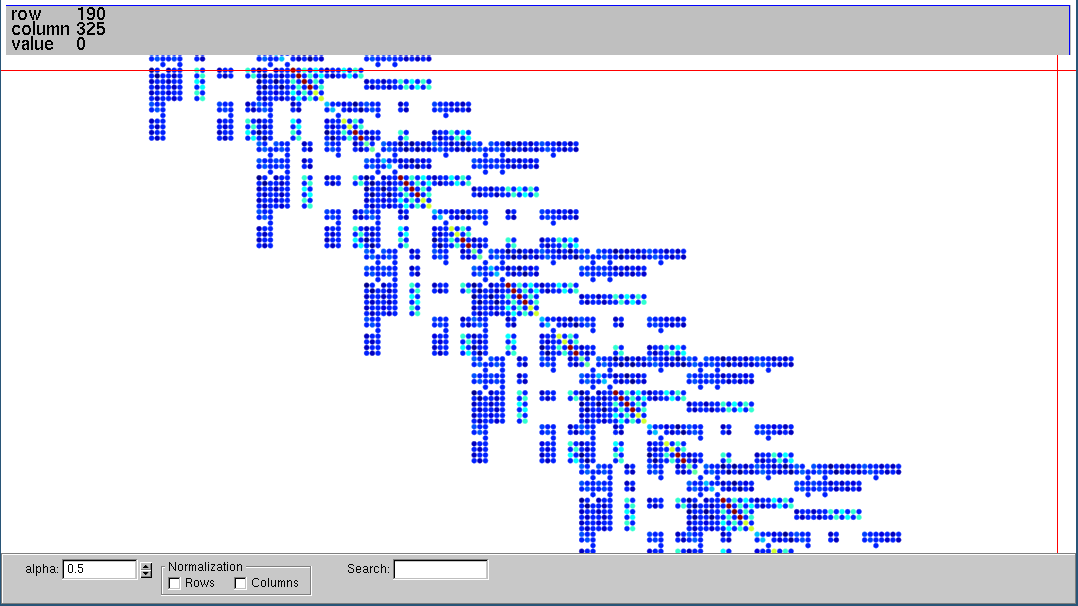
See the documentation for further information:
- russell_sparse documentation - Contains the API reference and examples
Installation
This crate depends on russell_lab, which, in turn, depends on an efficient BLAS library such as OpenBLAS and Intel MKL. This crate also depends on UMFPACK, MUMPS, and, optionally, on Intel DSS.
The root README file presents the steps to install the required dependencies.
Setting Cargo.toml

👆 Check the crate version and update your Cargo.toml accordingly:
[]
= "*"
Examples
See also:
Solve a tiny sparse linear system using UMFPACK
use ;
use *;
use StrError;
See russell_sparse documentation for more examples.
See also the folder examples.
Tools
This crate includes a tool named solve_matrix_market to study the performance of the available sparse solvers (currently MUMPS and UMFPACK).
solve_matrix_market reads a Matrix Market file and solves the linear system:
A ⋅ x = b
where the right-hand side (b) is a vector containing only ones.
The data directory contains an example of a Matrix Market file named bfwb62.mtx, and you may download more matrices from https://sparse.tamu.edu/
For example, run the command:
Or
to see the options.
The default solver of solve_matrix_market is UMFPACK. To run with MUMPS, use the --genie (-g) flag:
The output looks like this:
MUMPS + OpenBLAS issue
We found that MUMPS + OpenBLAS enters an infinite loop when the number of OpenMP threads is left to be automatically set.
This issue has also been discovered by 1, who states (page 72) "We have observed that multi-threading of OpenBLAS library in MUMPS leads to multiple thread conflicts which sometimes result in significant slow-down of the solver."
Therefore, we have to take one of the two approaches:
- If fixing the number of OpenMP threads for MUMPS, set the number of OpenMP threads for OpenBLAS to 1
- If fixing the number of OpenMP threads for OpenBLAS, set the number of OpenMP threads for MUMPS to 1
This issue has not been noticed with MUMPS + Intel MKL.
References
- Dorozhinskii R (2019) Configuration of a linear solver for linearly implicit time integration and efficient data transfer in parallel thermo-hydraulic computations. Master's Thesis in Computational Science and Engineering. Department of Informatics Technical University of Munich.
Benchmarks
Performance of MUMPS with Intel MKL and Flan_1565 matrix
We ran solve_matrix_market with MUMPS and the Flan_1565 matrix. The following combinations regarding the number of OpenMP threads have been investigated:
- Fixed MUMPS number of threads given to
ICNTL(16)with varying OpenBLAS/Intel MKL threads - Fixed OpenBLAS/Intel MKL threads with varying number of threads given to
ICNTL(16)
The results are shown below and illustrated in the following figures:
... intel-mkl ... varying blas threads ...
nt = 1 time = 1m10.065037815s error = 2.37e-8
nt = 2 time = 50.301718466s error = 2.06e-8
nt = 4 time = 39.741839403s error = 2.32e-8
nt = 8 time = 38.189990514s error = 2.41e-8
... openblas-compiled ... varying blas threads ...
nt = 1 time = 3m392.844321ms error = 1.30e-8
nt = 2 time = 1m49.896792253s error = 1.13e-8
nt = 4 time = 1m14.254609308s error = 1.07e-8
nt = 8 time = 56.196909085s error = 1.08e-8
... openblas-debian ... varying blas threads ...
nt = 1 time = 3m31.284256374s error = 1.07e-8
nt = 2 time = 2m5.60354019s error = 1.16e-8
nt = 4 time = 1m25.4454656s error = 1.12e-8
nt = 8 time = 1m549.305832ms error = 1.12e-8
... intel-mkl ... varying mumps threads ...
nt = 1 time = 1m10.964878104s error = 2.37e-8
nt = 2 time = 1m11.216798665s error = 2.37e-8
nt = 4 time = 1m10.026904288s error = 2.37e-8
nt = 8 time = 1m23.969941193s error = 2.37e-8
... openblas-compiled ... varying mumps threads ...
nt = 1 time = 2m59.416660889s error = 1.30e-8
nt = 2 time = 2m53.496207788s error = 1.30e-8
nt = 4 time = 2m49.55832447s error = 1.30e-8
nt = 8 time = 2m46.504678404s error = 1.30e-8
... openblas-debian ... varying mumps threads ...
nt = 1 time = 3m28.419395669s error = 1.21e-8
nt = 2 time = 3m37.610690768s error = 1.13e-8
nt = 4 time = 3m38.084725248s error = 1.09e-8
nt = 8 time = 3m22.981406305s error = 1.03e-8
Intel MKL with varying BLAS threads

Intel MKL with varying MUMPS-ICNTL(16) threads

Locally compiled MUMPS with varying BLAS threads

Locally compiled MUMPS with varying MUMPS-ICNTL(16) threads

Debian MUMPS with varying BLAS threads

Debian MUMPS with varying MUMPS-ICNTL(16) threads

Conclusions
- The fastest run happened with Intel MKL and varying BLAS threads while keeping MUMPS-ICNTL(16) constant and equal to 1.
- There is no speedup by changing MUMPS-ICNTL(16).
- The locally compiled compiled library is slightly faster than the one provided by Debian.
- The speedup with the best run is much worse than the ideal! With 8 threads, we cannot even get a 2x speedup.
The code to analyze the results and generate the figures is available here: benchmark-russell-sparse.
For developers
- The
c_codedirectory contains a thin wrapper to the sparse solvers (MUMPS, UMFPACK, and Intel DSS) - The
build.rsfile uses the crateccto build the C-wrappers - The
zscriptsdirectory also contains following:memcheck.bash: Checks for memory leaks on the C-code using Valgrindrun-examples: Runs all examples in theexamplesdirectoryrun-solve-matrix-market.bash: Runs the solve-matrix-market tool from thebindirectory