# DataProfiler 📊
[](https://github.com/AndreaBozzo/dataprof/actions)
[](LICENSE)
[](https://www.rust-lang.org)
[](https://crates.io/crates/dataprof)
[](https://pypi.org/project/dataprof/)
**DISCLAIMER FOR HUMAN READERS**
dataprof, even if working, is in early-stage development, therefore you might encounter bugs, minor or even major ones during your data-quality exploration journey.
Report them appropriately by opening an issue or by mailing the maintainer for security issues.
Thanks for your time here!
**High-performance data quality and ML readiness assessment library**
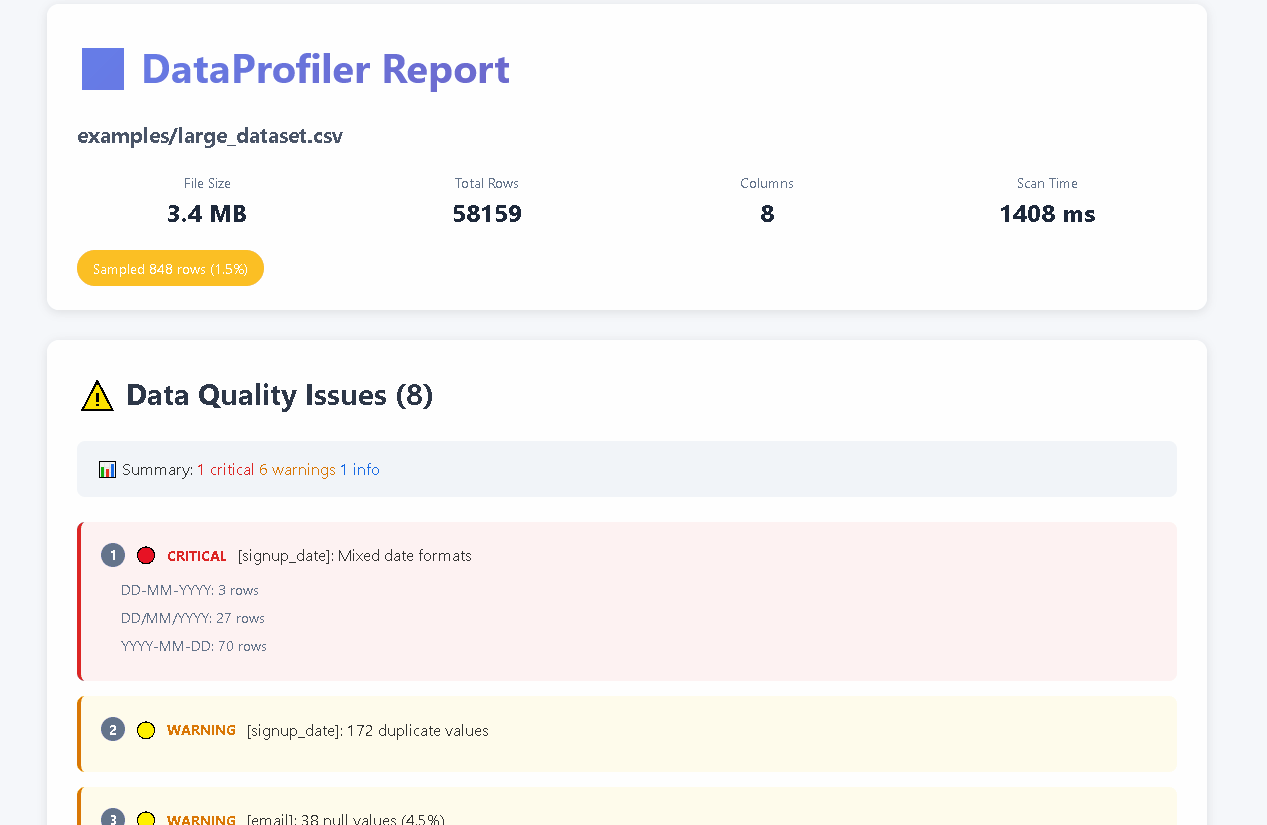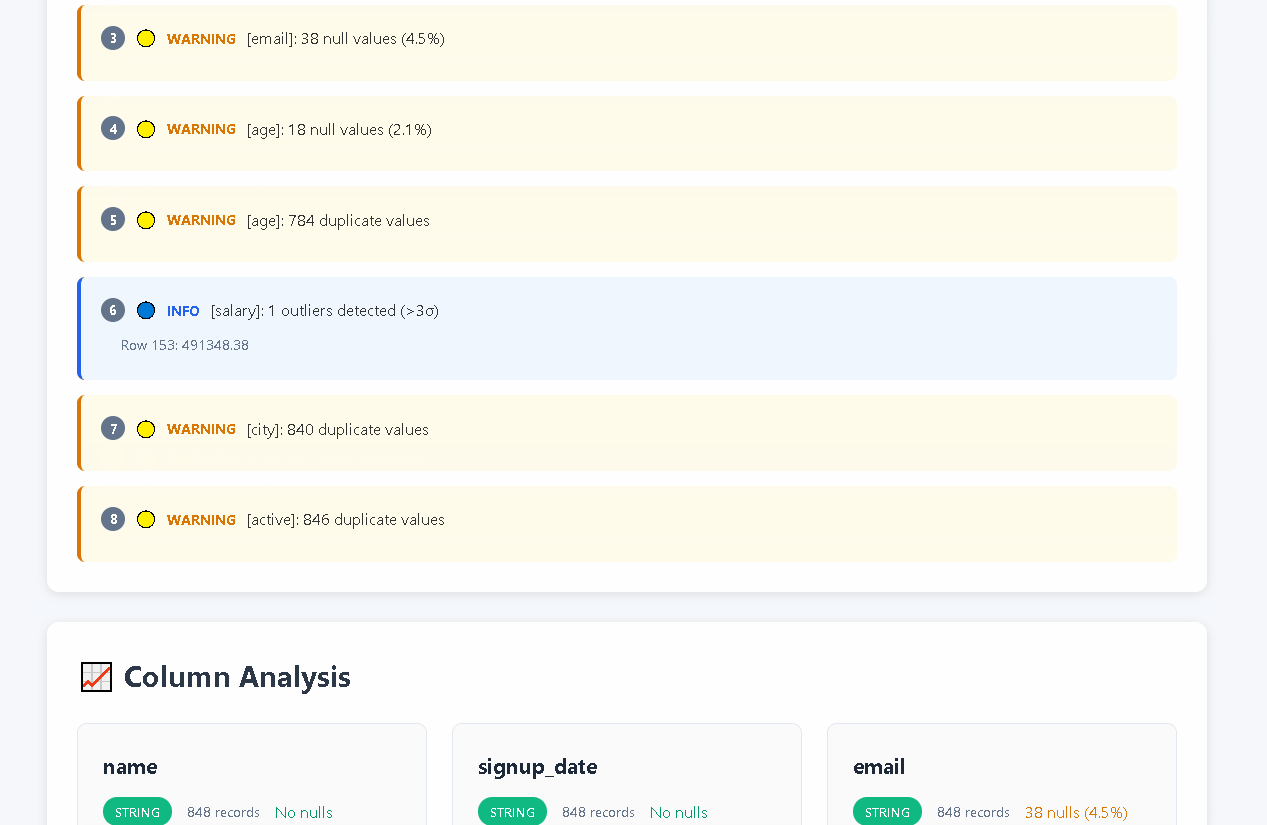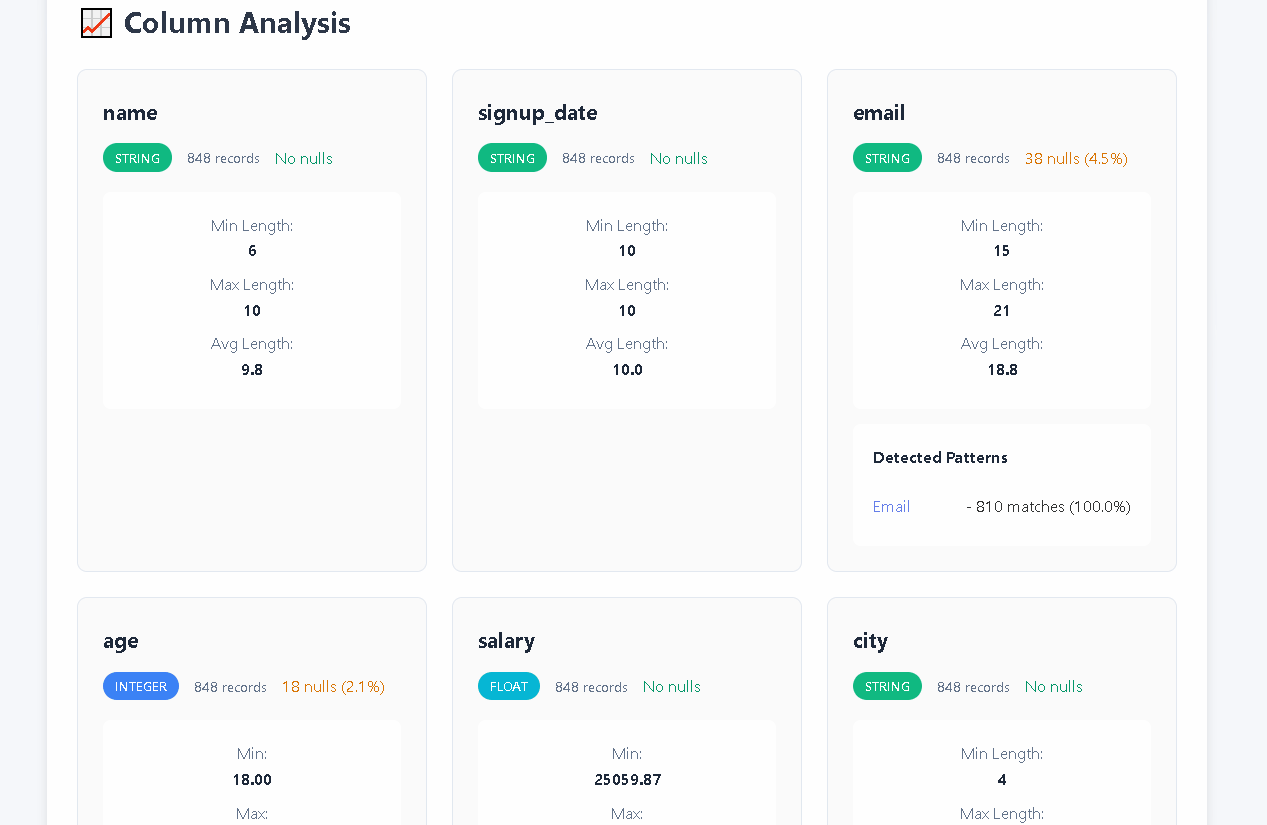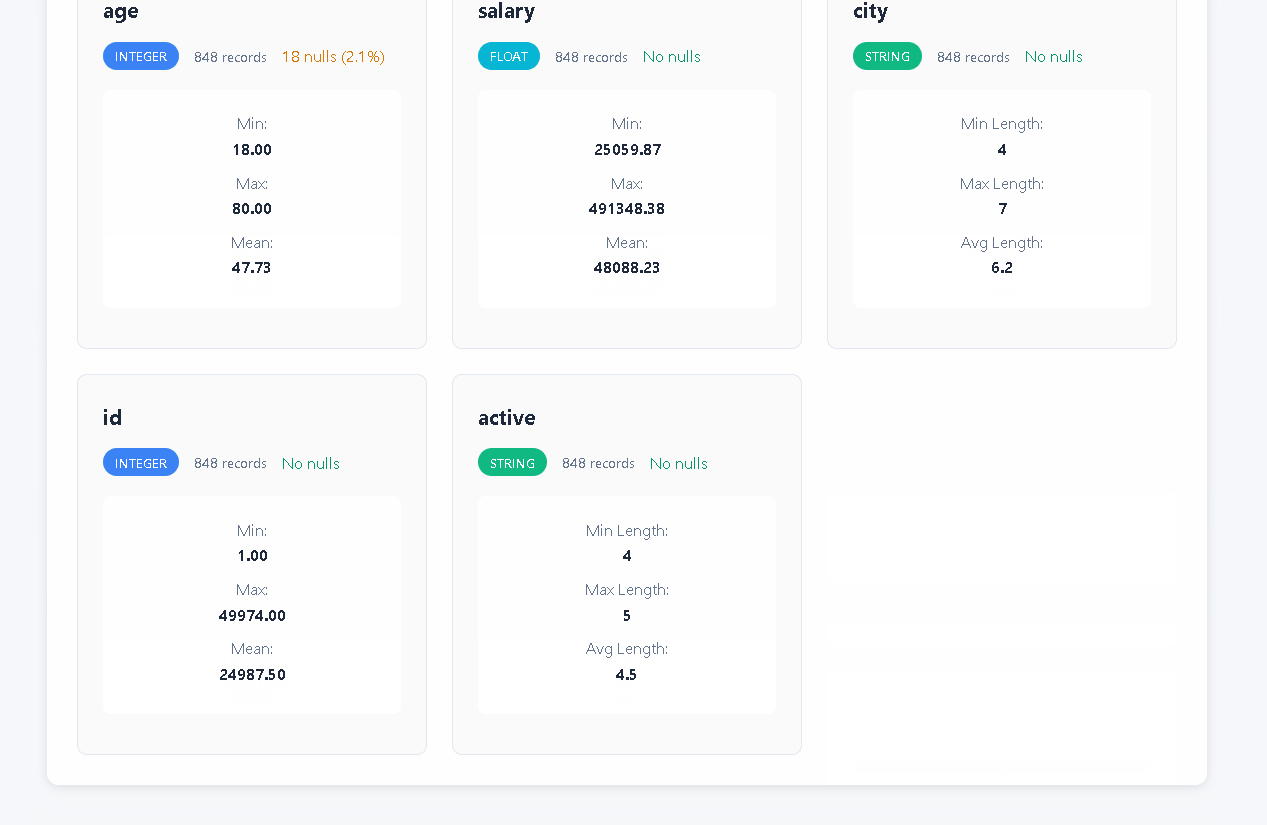
DataProfiler v0.4.4 delivers 20x better memory efficiency than pandas, unlimited file streaming, 30+ automated quality checks, and **NEW: comprehensive ML readiness assessment**. Built in Rust with full Python bindings and production-ready database connectivity.

## ✨ Key Features (v0.4.4)
- **🤖 ML Readiness Assessment**: Automated feature analysis, blocking issues detection, preprocessing recommendations
- **⚡ High Performance**: 20x more memory efficient than pandas with Apache Arrow integration
- **🌊 Scalable**: Stream processing for files larger than RAM (tested up to 100GB)
- **🔍 Smart Quality Detection**: 30+ automated checks for nulls, duplicates, outliers, format issues
- **🗃️ Production Database Support**: PostgreSQL, MySQL, SQLite, DuckDB with SSL/TLS and retry logic
- **🐍 Complete Python Integration**: Native bindings with pandas, scikit-learn, Jupyter support
## 🚀 Quick Start
### Python
```bash
pip install dataprof
```
```python
import dataprof
# NEW v0.4.4: ML readiness assessment
ml_score = dataprof.ml_readiness_score("data.csv")
print(f"ML Readiness: {ml_score.readiness_level} ({ml_score.overall_score:.1f}%)")
# Quality analysis with detailed reporting
report = dataprof.analyze_csv_with_quality("data.csv")
print(f"Quality score: {report.quality_score():.1f}%")
# Production database profiling with SSL
profiles = dataprof.analyze_database("postgresql://user:pass@host/db", "users")
```
### Rust
```bash
cargo add dataprof --features arrow
```
```rust
use dataprof::*;
// High-performance Arrow processing
let profiler = DataProfiler::columnar();
let report = profiler.analyze_csv_file("large_dataset.csv")?;
```
### CLI
```bash
# Basic profiling
dataprof data.csv --quality --html report.html
# Database profiling
dataprof users --database "postgresql://user:pass@host:5432/db" --quality
# Large files with progress
dataprof huge_file.csv --streaming --progress
```
## 📊 Performance
| **DataProfiler (Arrow)** | **0.5s** | 30MB | ✅ 30+ checks | ✅ |
| DataProfiler (Standard) | 2.1s | 45MB | ✅ 30+ checks | ✅ |
| pandas.describe() | 8.4s | 380MB | ❌ Basic stats | ❌ |
| Great Expectations | 12.1s | 290MB | ✅ Rule-based | ❌ |
## 💡 Real-World Examples
**NEW v0.4.4: ML Pipeline Integration**
```python
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.pipeline import Pipeline
import dataprof
# Step 1: ML readiness assessment guides preprocessing
ml_score = dataprof.ml_readiness_score("dataset.csv")
features_df = dataprof.feature_analysis_dataframe("dataset.csv")
# Step 2: Auto-categorize features for scikit-learn pipeline
numeric_features = features_df[features_df['feature_type'] == 'numeric']['column_name'].tolist()
categorical_features = features_df[features_df['feature_type'] == 'categorical']['column_name'].tolist()
# Step 3: Build preprocessing pipeline based on DataProf recommendations
preprocessor = Pipeline([
('scaler', StandardScaler()) # Applied to numeric features
])
print(f"✅ Pipeline ready with {len(numeric_features)} numeric, {len(categorical_features)} categorical features")
```
**Production Quality Gate**
```python
from dataprof import quick_quality_check, ml_readiness_score
def validate_ml_pipeline_data(file_path):
quality_score = quick_quality_check(file_path)
ml_score = ml_readiness_score(file_path)
if quality_score < 85.0:
raise Exception(f"Data quality too low: {quality_score:.1f}%")
if ml_score.overall_score < 70.0:
raise Exception(f"ML readiness too low: {ml_score.overall_score:.1f}%")
return quality_score, ml_score.overall_score
```
**Database Monitoring with ML Assessment**
```bash
# Monitor daily data loads with ML readiness
dataprof daily_sales --database "postgresql://user:pass@prod-db/warehouse" \
--query "SELECT * FROM sales WHERE date = CURRENT_DATE" \
## 📖 Documentation
| **[Python API Reference](docs/python/API_REFERENCE.md)** | Complete function and class reference |
| **[ML Features Guide](docs/python/ML_FEATURES.md)** | NEW: ML readiness assessment and preprocessing recommendations |
| **[Python Integrations](docs/python/INTEGRATIONS.md)** | Pandas, scikit-learn, Jupyter, Airflow workflows |
| **[Database Connectors](docs/database-connectors.md)** | Production PostgreSQL, MySQL, SQLite, DuckDB with SSL/TLS |
| **[CLI Usage Guide](docs/CLI_USAGE_GUIDE.md)** | Comprehensive CLI with progress indicators and validation |
Resources: [CHANGELOG](CHANGELOG.md) • [CONTRIBUTING](CONTRIBUTING.md) • [LICENSE](LICENSE)
## 🛠️ Development
```bash
git clone https://github.com/AndreaBozzo/dataprof.git
cd dataprof
# Quick setup
bash scripts/setup-dev.sh # Linux/macOS
pwsh scripts/setup-dev.ps1 # Windows
# Build and test
cargo build --release
cargo test --all
```
## 🤝 Contributing
We welcome contributions! Please see [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
- 🐛 [Report bugs](https://github.com/AndreaBozzo/dataprof/issues)
- ✨ [Request features](https://github.com/AndreaBozzo/dataprof/issues)
- 📖 [Improve docs](https://github.com/AndreaBozzo/dataprof/wiki)
## 📄 License
Licensed under [GPL-3.0](LICENSE) • Commercial use allowed with source disclosure