[−][src]Crate fasteval
A fast algebraic expression evaluation library.
Built-in Functions and Constants
* print(...strings and values...) -- Prints to stderr. Very useful to 'probe' an expression.
Evaluates to the last value.
Example: `print("x is", x, "and y is", y)`
Example: `x + print("y:",y) + z == x+y+z`
* log(base=10, val) -- Logarithm with optional 'base' as first argument.
Example: `log(100) + log(e(),100)`
* e() -- Euler's number (2.718281828459045)
* pi() -- π (3.141592653589793)
* int(val)
* ceil(val)
* floor(val)
* round(modulus=1, val) -- Round with optional 'modulus' as first argument.
Example: `round(1.23456) == 1 && round(0.001, 1.23456) == 1.235`
* abs(val)
* sign(val)
* min(val, ...) -- Example: `min(1,-2,3,-4) == -4`
* max(val, ...) -- Example: `max(1,-2,3,-4) == 3`
* sin(radians) * asin(val)
* cos(radians) * acos(val)
* tan(radians) * atan(val)
* sinh(val) * asinh(val)
* cosh(val) * acosh(val)
* tanh(val) * atanh(val)
Examples
Easy evaluation of constant expressions
The ez_eval() function performs the entire allocation-parse-eval process
for you. It is a little bit inefficient because it always allocates a
fresh Slab, but it is very simple to use:
fn main() -> Result<(), fasteval::Error> { let val = fasteval::ez_eval( "1+2*3/4^5%6 + log(100) + log(e(),100) + [3*(3-3)/3] + (2<3) && 1.23", &mut fasteval::EmptyNamespace)?; // | | | | | | | // | | | | | | boolean logic with ternary support // | | | | | comparisons // | | | | square-brackets act like parenthesis // | | | built-in constants: e(), pi() // | | 'log' can take an optional first 'base' argument, defaults to 10 // | many built-in functions: print, int, ceil, floor, abs, sign, log, round, min, max, sin, asin, ... // standard binary operators assert_eq!(val, 1.23); Ok(()) }
Simple variables
Several namespace types are supported, each designed for different
situations. (See the various Namespace types here.) For simple cases, you can define variables with a BTreeMap:
use std::collections::BTreeMap; fn main() -> Result<(), fasteval::Error> { let mut map : BTreeMap<String,f64> = BTreeMap::new(); map.insert("x".to_string(), 1.0); map.insert("y".to_string(), 2.0); map.insert("z".to_string(), 3.0); let val = fasteval::ez_eval(r#"x + print("y:",y) + z"#, &mut map)?; // | // prints "y: 2" to stderr and then evaluates to 2.0 assert_eq!(val, 6.0); Ok(()) }
Advanced variables and custom functions
This time, instead of using a map, we will use a namespace with a callback function, which enables us to do advanced things, like define custom functions and array-like objects:
fn main() -> Result<(), fasteval::Error> { let mut ns = fasteval::CachedFlatNamespace::new(|name:&str, args:Vec<f64>| -> Option<f64> { let mydata : [f64; 3] = [11.1, 22.2, 33.3]; match name { "x" => Some(3.0), "y" => Some(4.0), "sum" => Some(args.into_iter().fold(0.0, |s,f| s+f)), "data" => args.get(0).and_then(|f| mydata.get(*f as usize).copied()), _ => None, } }); let val = fasteval::ez_eval("sum(x^2, y^2)^0.5 + data[0]", &mut ns)?; // | | | // | | square-brackets act like parenthesis // | variables are like custom functions with zero args // custom function assert_eq!(val, 16.1); Ok(()) }
Re-use the Slab to go faster
If we perform the parse and eval ourselves (without relying on the 'ez' interface), then we can re-use the Slab allocation for subsequent parsing and evaluations. This avoids a significant amount of slow memory operations:
use std::collections::BTreeMap; use fasteval::Evaler; // import this trait so we can call eval(). fn main() -> Result<(), fasteval::Error> { let mut slab = fasteval::Slab::new(); let expr_ref = fasteval::parse("x + 1", &mut slab.ps)?.from(&slab.ps); // Let's evaluate the expression a couple times with different 'x' values: let mut map : BTreeMap<String,f64> = BTreeMap::new(); map.insert("x".to_string(), 1.0); let val = expr_ref.eval(&slab, &mut map)?; assert_eq!(val, 2.0); map.insert("x".to_string(), 2.5); let val = expr_ref.eval(&slab, &mut map)?; assert_eq!(val, 3.5); // Now, let's re-use the Slab for a new expression. // (This is much cheaper than allocating a new Slab.) slab.clear(); let expr_ref = fasteval::parse("x * 10", &mut slab.ps)?.from(&slab.ps); let val = expr_ref.eval(&slab, &mut map)?; assert_eq!(val, 25.0); Ok(()) }
Compile to go super fast!
If you plan to evaluate an expression just one or two times, then you should parse-eval as shown in previous examples. But if you expect to evaluate an expression three or more times, you can dramatically improve your performance by compiling. The compiled form is usually more than 10 times faster than the un-compiled form, and for constant expressions it is usually more than 200 times faster.
use std::collections::BTreeMap; use fasteval::Compiler; // import this trait so we can call compile(). use fasteval::Evaler; // import this trait so we can call eval(). fn main() -> Result<(), fasteval::Error> { let mut slab = fasteval::Slab::new(); let mut map = BTreeMap::new(); let expr_str = "sin(deg/360 * 2*pi())"; let compiled = fasteval::parse(expr_str, &mut slab.ps)?.from(&slab.ps).compile(&slab.ps, &mut slab.cs); for deg in 0..360 { map.insert("deg".to_string(), deg as f64); // When working with compiled constant expressions, you can use the // eval_compiled*!() macros to save a function call: let val = fasteval::eval_compiled!(compiled, &slab, &mut map); eprintln!("sin({}°) = {}", deg, val); } Ok(()) }
Unsafe Variables
If your variables must be as fast as possible and you are willing to be
very careful, you can build with the unsafe-vars feature (cargo build --features unsafe-vars), which enables pointer-based variables. These
unsafe variables perform 2x-4x faster than the compiled form above. This
feature is not enabled by default because it slightly slows down other
non-variable operations.
use fasteval::Compiler; // import this trait so we can call compile(). use fasteval::Evaler; // import this trait so we can call eval(). fn main() -> Result<(), fasteval::Error> { let mut slab = fasteval::Slab::new(); let mut deg : f64 = 0.0; unsafe { slab.ps.add_unsafe_var("deg".to_string(), °); } // Saves a pointer to 'deg'. let mut ns = fasteval::EmptyNamespace; // We only define unsafe variables, not normal variables, // so EmptyNamespace is fine. let expr_str = "sin(deg/360 * 2*pi())"; let compiled = fasteval::parse(expr_str, &mut slab.ps)?.from(&slab.ps).compile(&slab.ps, &mut slab.cs); for d in 0..360 { deg = d as f64; let val = fasteval::eval_compiled!(compiled, &slab, &mut ns); eprintln!("sin({}°) = {}", deg, val); } Ok(()) }
Performance Benchmarks
These benchmarks were performed on 2019-12-25.
Here are links to all the libraries/tools included in these benchmarks:
Charts
Note that the following charts use logarithmic scales. Therefore, tiny visual differences actually represent very significant performance differences.
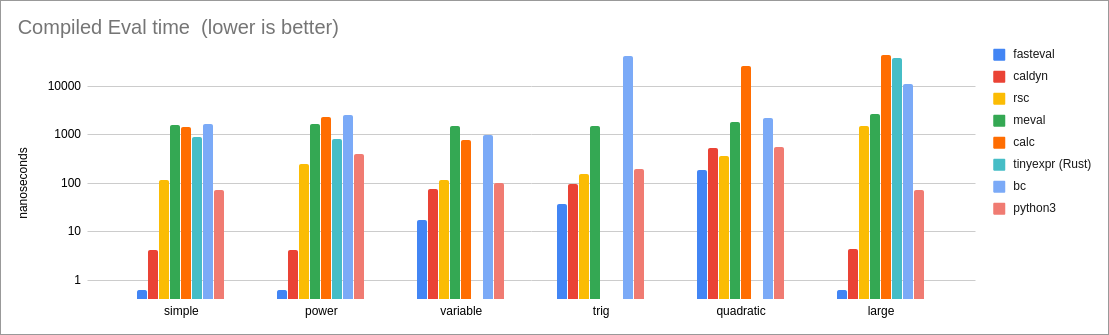
Performance of evaluation of a compiled expression:
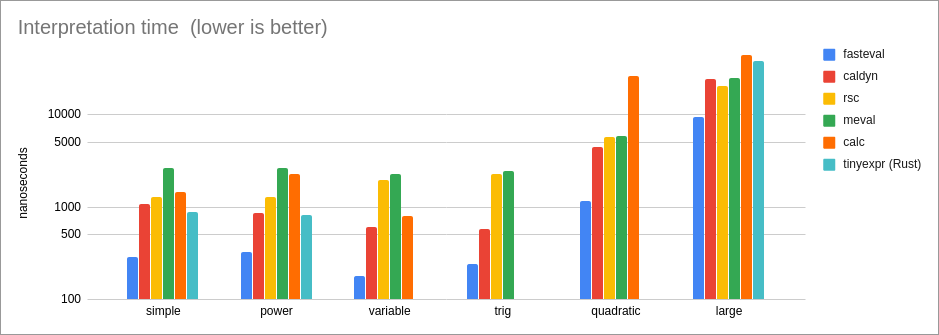
Performance of one-time interpretation (parse and eval):
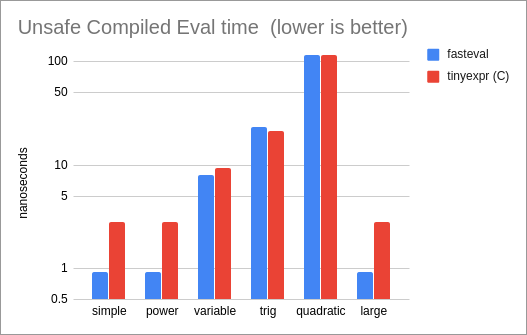
Performance of compiled Unsafe Variables, compared to the tinyexpr C library (the
only other library in our test set that supports this mode):
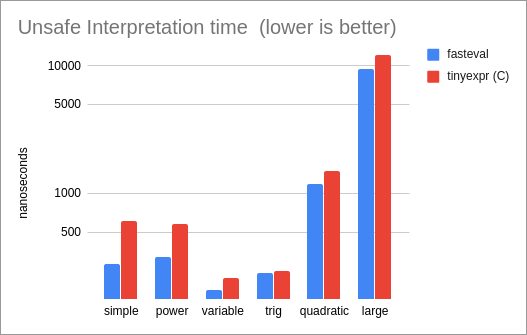
Performance of interpreted Unsafe Variables, compared to the tinyexpr C library (the
only other library in our test set that supports this mode):
Summary
The impressive thing about these results is that 'fasteval' consistently achieves the fastest times across every benchmark and in every mode of operation (interpreted, compiled, and unsafe). It's easy to create a design to claim the #1 spot in any one of these metrics by sacrificing performance in another, but it is difficult to create a design that can be #1 across-the-board.
Because of the broad and robust performance advantages, 'fasteval' is very likely to be an excellent choice for your dynamic evaluation needs.
Benchmark Descriptions & Analysis
* simple = `3 * 3 - 3 / 3`
This is a simple test with primitive binary operators.
Since the expression is quite simple, it does a good job of showing
the intrinsic performance costs of a library.
Results:
* For compiled expressions, 'fasteval' is 6x as fast as the closest
competitor (caldyn) because the `eval_compiled!()` macro is able to
eliminate all function calls. If the macro is not used and a
normal `expr.eval()` function call is performed instead, then
performance is very similar to caldyn's.
* For interpreted expressions, 'fasteval' is 2x as fast as the
tinyexpr C lib, and 3x as fast as the tinyexpr Rust lib.
This is because 'fasteval' eliminates redundant work and memory
allocation during the parse phase.
* power = `2 ^ 3 ^ 4`
`2 ^ (3 ^ 4)` for 'tinyexpr' and 'rsc'
This test shows the associativity of the exponent operator.
Most libraries (including 'fasteval') use right-associativity,
but some libraries (particularly tinyexpr and rsc) use
left-associativity.
This test is also interesting because it shows the precision of a
library's number system. 'fasteval' just uses f64 and therefore truncates
the result (2417851639229258300000000), while python, bc, and the
tinyexpr C library produce a higher precision result
(2417851639229258349412352).
Results:
Same as the 'simple' case.
* variable = `x * 2`
This is a simple test of variable support.
Since the expression is quite simple, it shows the intrinsic
performance costs of a library's variables.
Results:
* The tinyexpr Rust library does not currently support variables.
* For safe compiled evaluation, 'fasteval' is 4.4x as fast as the closest
competitor (caldyn).
* For safe interpretation, 'fasteval' is 3.3x as fast as the closest
competitor (caldyn).
* For unsafe variables, 'fasteval' is 1.2x as fast as the
tinyexpr C library.
* trig = `sin(x)`
This is a test of variables, built-in function calls, and trigonometry.
Results:
* The tinyexpr Rust library does not currently support variables.
* The 'calc' library does not support trigonometry.
* For safe compiled evaluation, 'fasteval' is 2.6x as fast as the
closest competitor (caldyn).
* For safe interpretation, 'fasteval' is 2.3x as fast as the closest
competitor (caldyn).
* Comparing unsafe variables with the tinyexpr C library,
'fasteval' is 8% slower for compiled expressions (tinyexpr uses a
faster 'sin' implementation) and 4% faster for interpreted
expressions ('fasteval' performs less memory allocation).
* quadratic = `(-z + (z^2 - 4*x*y)^0.5) / (2*x)`
This test demonstrates a more complex expression, involving several
variables, some of which are accessed more than once.
Results:
* The tinyexpr Rust library does not currently support variables.
* For safe compiled evaluation, 'fasteval' is 2x as fast as the
closest competitor (rsc).
* For safe interpretation, 'fasteval' is 3.7x as fast as the
closest competitor (caldyn).
* Comparing unsafe variables with the tinyexpr C library,
'fasteval' is the same speed for compiled expressions,
and 1.2x as fast for interpretation.
* big = `((((87))) - 73) + (97 + (((15 / 55 * ((31)) + 35))) + (15 - (9)) - (39 / 26) / 20 / 91 + 27 / (33 * 26 + 28 - (7) / 10 + 66 * 6) + 60 / 35 - ((29) - (69) / 44 / (92)) / (89) + 2 + 87 / 47 * ((2)) * 83 / 98 * 42 / (((67)) * ((97))) / (34 / 89 + 77) - 29 + 70 * (20)) + ((((((92))) + 23 * (98) / (95) + (((99) * (41))) + (5 + 41) + 10) - (36) / (6 + 80 * 52 + (90))))`
This is a fairly large expression that highlights parsing costs.
Results:
* Since there are no variables in the expression, 'fasteval' and
'caldyn' compile this down to a single constant value. That's
why these two libraries are so much faster than the rest.
* For compiled evaluation, 'fasteval' is 6x as fast as 'caldyn'
because it is able to eliminate function calls with the
`eval_compiled!()` macro.
* For interpretation, 'fasteval' is 2x as fast as the closest
competitor (rsc).
* Comparing unsafe variables with the tinyexpr C library,
'fasteval' is 3x as fast for compiled evaluation, and
1.2x as fast for interpretation.
Methodology
I am running Ubuntu 18.04 on an Asus G55V (a 2012 laptop with Intel Core i7-3610QM CPU @ 2.3GHz - 3.3GHz).
All numeric results can be found in fasteval/benches/bench.rs.
Disable Power Saving Mode
for F in /sys/devices/system/cpu/cpufreq/policy*/scaling_governor; do echo $F; cat $F; done for F in /sys/devices/system/cpu/cpufreq/policy*/scaling_governor; do echo performance >$F; done
Always Use RUSTFLAGS="--emit=asm"
For some reason which I have been unable to find any documentation about, the emission of assembly code during compilation causes LLVM to dramatically improve the optimization of the resulting binary (often a 3x difference for critical sections!). In particular, it makes better choices regarding variable localization and function inlining. I suggest that you always use this option for everything you do.
Layout Randomization
I use a poor-man's Layout Randomization method similar to Coz. The size and location of your code has significant impact on its performance. The compiler often makes poor decisions about code placement, which results in up to 40% performance differences! When benchmarking, it is important to remove this source of noise so that you can see the real effects of your changes.
Rather than using Coz, I use a poor-man's approach which has no dependencies and works across languages: During each iteration of my benchmark loop, I inject a random number of no-op instructions into my benchmark code (using 'sed'). This shifts everything around in the address space so that I end up hitting all fast and slow scenarios.
I then run the benchmark loop many times, keeping track of the fastest-seen times until I no longer observe any improvements in any part of the banchmark suite for 500 seconds. At that point, I say that I have reached a stable point and can draw conclusions from the statistics.
Here is my benchmark loop, which performs Layout Randomization:
while true; do echo "time: $(date +%s)"; cat benches/bench.rs.tmpl | sed "s|//SHIFT_CODE|$( N=$(( 1 + $RANDOM % 1024 )); while [[ $N > 0 ]]; do N=$(( $N - 1 )); echo -n 'let x=black_box(x+1);'; done )|g" >benches/bench.rs; RUSTFLAGS="--emit=asm" cargo bench; done >bench.out
I monitor the results with this:
cat bench.out | awk -v "now=$(date +%s)" '$1=="time:"{when=$2} $3=="..." && $4=="bench:" {gsub(/,/, "", $5); v=$5+0; if (t[$2]=="" || v<t[$2]){t[$2]=v; w[$2]=when;}} END{for (k in t) { printf "%-40s %9d ns/iter %5ds ago\n",k,t[k],now-w[k] }}' | sort
How is fasteval so fast?
A variety of techniques are used to optimize performance:
- Minimization of memory allocations/deallocations; I just pre-allocate a large slab during initialization.
- Elimination of redundant work, especially when parsing.
- Compilation: Constant Folding and Expression Simplification. Boosts performance up to 1000x.
- Profile-driven application of inlining. Don't inline too much or too little.
- Use of macros to eliminate call overhead for the most-frequently-used functions. (Macros are often more efficient than inlined functions.)
- Don't
panic!(). If anything in your code can panic, then much code must be run on every function call to handle stack unwinding. - Localize variables. Use "--emit asm" as a guide.
Can fasteval be faster?
Yes, but not easily, and not by much.
To boost the 'eval' phase, we would really need to perform compilation to machine code, which is difficult and non-portable across platforms. Also, the potential gains are limited: We already run at half-the-speed-of-compiled-optimized-Rust for constant expressions (the most common case). So for constant expressions, the most you could gain from compilation-to-machine-code is a 2x performance boost. We are already operating close to the theoretical limit!
It is possible to perform faster evaluation of non-constant expressions by introducing more constraints or complexity:
- If I introduce a 'const' var type, then I can transform variable expressions into constant expressions. I don't think this would be useful-enough in real-life to justify the extra complexity.
- Evaluation could be paralellized (with a more complex design).
It is possible to boost overall speed by improving the parsing algoritm to produce a Reverse Polish Notation AST directly, rather than the currennt infix AST which is then converted to RPN during compilation. However, this isn't as simple as just copying the Shunting-Yard algorithm because I support more advanced (and customizable) syntax (such as function calls and strings), while Shunting-Yard is designed only for algebraic expressions.
Re-exports
pub use self::error::Error; |
pub use self::parser::parse; |
pub use self::parser::Parser; |
pub use self::parser::Expression; |
pub use self::parser::ExpressionI; |
pub use self::parser::Value; |
pub use self::parser::ValueI; |
pub use self::compiler::Compiler; |
pub use self::compiler::Instruction; |
pub use self::compiler::Instruction::IConst; |
pub use self::compiler::InstructionI; |
pub use self::evaler::Evaler; |
pub use self::slab::Slab; |
pub use self::evalns::EvalNamespace; |
pub use self::evalns::Layered; |
pub use self::evalns::EmptyNamespace; |
pub use self::evalns::CachedFlatNamespace; |
pub use self::evalns::CachedScopedNamespace; |
pub use self::evalns::Bubble; |
pub use self::ez::ez_eval; |
Modules
| compiler | |
| error | This module contains |
| evaler | |
| evalns | |
| ez | |
| parser | |
| slab | A |
Macros
| bool_to_f64 | |
| eval_compiled | |
| eval_compiled_ref | |
| f64_eq | |
| f64_ne |