# Train Station
[](https://github.com/ewhinery8/train-station/actions/workflows/ci.yml)
[](https://github.com/ewhinery8/train-station/actions/workflows/ci-linux.yml)
[](https://github.com/ewhinery8/train-station/actions/workflows/ci-windows.yml)
[](https://github.com/ewhinery8/train-station/actions/workflows/ci-macos.yml)
[](https://github.com/ewhinery8/train-station/actions/workflows/release.yml)
[](https://github.com/ewhinery8/train-station#platform-support)
[](https://github.com/ewhinery8/train-station/actions/workflows/cross-compile.yml)
[](https://crates.io/crates/train-station)
[](https://docs.rs/train-station)
[](https://github.com/ewhinery8/train-station#license)
[](https://blog.rust-lang.org/2023/06/01/Rust-1.70.0.html)
> A zero-dependency, PyTorch-inspired, maximum-performance Rust machine learning library.
### Table of Contents
- [Why Train Station](#why-train-station)
- [Quick Start](#quick-start)
- [Examples](#examples)
- [Standout Architecture](#standout-architecture)
- [SIMD-aligned TensorMemoryPool](#simd-aligned-tensormemorypool)
- [Safe, zero-copy View system](#safe-zero-copy-view-system)
- [Iterator-first API](#iterator-first-api)
- [Thread-safe GradTrack](#thread-safe-gradtrack)
- [Broadcasting](#broadcasting)
- [Operations & Capabilities](#operations--capabilities)
- [Performance](#performance)
- [Install & Platform Support](#install--platform-support)
- [Links](#links)
- [CUDA Status](#cuda-status)
- [Roadmap](#roadmap)
### Why Train Station
- **Zero dependencies**: pure Rust, no BLAS/MKL or FFI required.
- **Performance**: AVX512/AVX2/SSE2 dispatch, cache-aware kernels, SIMD-aligned memory.
- **Research-ready**: clean, explicit primitives for novel layers/architectures.
- **Safety with control**: zero-copy views, copy-on-write on mutation, bounds-checked access.
- **PyTorch-inspired API**: intentionally mirrors PyTorch semantics so users can transfer skills/code patterns easily; iterators integrate with autograd.
Train Station’s purpose is to advance research. It provides low-level control and simple, composable building blocks so you can construct larger objects and full networks with confidence. We aim to be a solid foundation for the next generation of AI architectures, training procedures, and systems.
Note on data types: the core currently targets `f32` tensors. We will expand to additional data types over time.
### Quick Start
```rust
use train_station::{Tensor, Device, Adam};
let x = Tensor::randn(vec![32, 784], None);
let w = Tensor::randn(vec![784, 128], None).with_requires_grad();
let b = Tensor::zeros(vec![128]).with_requires_grad();
let y = x.matmul(&w).add_tensor(&b).relu();
let loss = y.sum();
loss.backward(None);
let mut opt = Adam::new();
opt.add_parameters(&[&w, &b]);
opt.step(&mut [&mut w, &mut b]);
```
### Examples
- Browse numerous runnable examples in the repository `examples/` folder:
- https://github.com/ewhinery8/train-station/tree/master/examples
### Standout Architecture
#### SIMD-aligned TensorMemoryPool
- Why it stands out
- **Predictable speedups** for small/medium tensors where alloc/free dominates.
- **SIMD-ready** memory guarantees mean kernels can use aligned loads/stores.
- **No foot-guns**: cross-thread drops are safe; pool returns gracefully to owner thread when possible.
- **No artificial limits**: pools grow with demand and trim idle capacity in the background.
- How it works
- **Thread-local pools** of ML-sized buffers (small/medium/large/xlarge) avoid contention.
- **Alignment by CPU**: runtime SIMD detection chooses 64/32/16-byte alignment.
- **Planned capacity**: requests round to lane multiples; xlarge grows exponentially for fewer system calls.
- **Cleanup gates**: trims only after enough ops and time have elapsed, preserving headroom to prevent thrash.
- **Controls**: `with_no_mem_pool` forces system allocation;
- **Threading note**: pools are thread-local; when returning tensors to another thread, prefer `with_no_mem_pool` for those allocations.
#### Safe, zero-copy View system
- Why it stands out
- **Zero-copy ergonomics** for common transforms without trading off safety.
- **Works with padding**: bounds are validated against true capacity, not just logical size.
- **Stable gradients**: view operations integrate with autograd for correct backprop.
- How it works
- **Allocation owner** is shared across views; shapes/strides remap without copying.
- **Capacity checks** ensure `as_strided`/slices stay in-bounds; offsets validated before construction.
- **Copy-on-write**: mutating a tensor with active views clones storage to protect view semantics.
- **Grad functions**: view APIs register mapping info so gradients are routed back to sources.
#### Iterator-first API
- Why it stands out
- **Idiomatic Rust**: compose tensor programs with the standard Iterator toolbox.
- **Zero-copy iteration**: yields views, not copies—great for slicing, windows, and batching.
- **Gradient-preserving** pipelines: transformations remain differentiable end-to-end.
- How it works
- **Rich iterator suite**: elements, dims, chunks (exact/remainder), windows, and value iterators.
- **Contiguity on demand**: stepped views auto-materialize contiguous buffers when needed.
- **SIMD copy paths**: collection routines use vectorized copy when alignment allows.
#### Thread-safe GradTrack
- Why it stands out
- **Production-ready**: safe in multi-thread pipelines and batched workers.
- **Efficient**: TLS fast-path for single-threaded training; shared sharded maps for parallelism.
- **Pragmatic controls**: retain, materialize, and precise clearing APIs.
- How it works
- **Graph groups**: operations bind to a local group; when needed, groups are unified into a shared, sharded graph.
- **Sharded maps**: operations/gradients stored across shards to reduce contention.
- **Accumulate gradients** with optimized tensor ops; reduction matches broadcasting semantics.
- **APIs**: `retain_grad`, `grad_or_fetch`, and `clear_*` helpers manage lifecycle deterministically.
#### Broadcasting
- Why it stands out
- **Frictionless** shape handling across nearly all element-wise ops.
- **Batched matmul** that scales from vectors to high-rank tensors.
- How it works
- **Zero-copy broadcast**: create aligned, same-shape views, then invoke optimized same-shape kernels.
- **Gradient reduction**: backward pass sums along broadcasted axes to recover source gradients.
- **Matmul classification**: validates dimensions and applies broadcasting across batch dims.
### Operations & Capabilities
| Element-wise | `add`, `sub`, `mul`, `div` | Yes (NumPy rules) | AVX2 (runtime dispatch) | Yes |
| Activations | `relu`, `leaky_relu`, `sigmoid`, `tanh`, `softmax` | N/A (shape-preserving) | ReLU/SQRT paths SIMD where applicable | Yes |
| Math | `exp`, `log`, `sqrt`, `pow` | N/A | `sqrt` SIMD; others optimized scalar | Yes |
| Matrix | `matmul` | Yes (batched ND) | AVX512/AVX2/SSE2 kernels | Yes |
| Transforms | `reshape`, `transpose`, `slice`, `as_strided`, `element_view` | Zero-copy views | N/A | Yes (view mappings) |
Notes:
- Runtime SIMD detection selects fastest available path; scalar fallbacks are optimized.
- Broadcasting creates zero-copy same-shape views, then executes SIMD same-shape kernels.
### Performance
Real-world, apples-to-apples comparisons vs LibTorch (CPU):
#### Addition
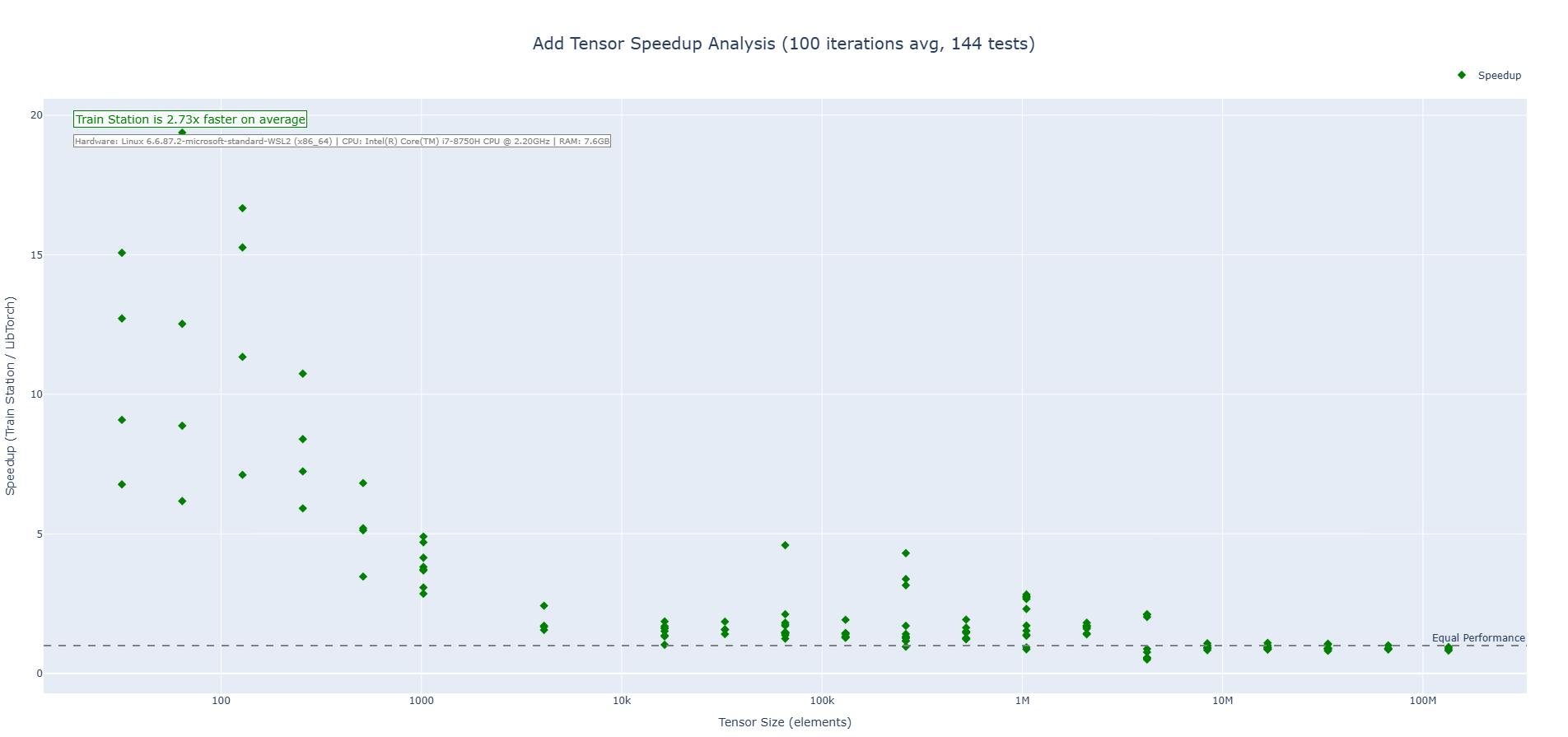
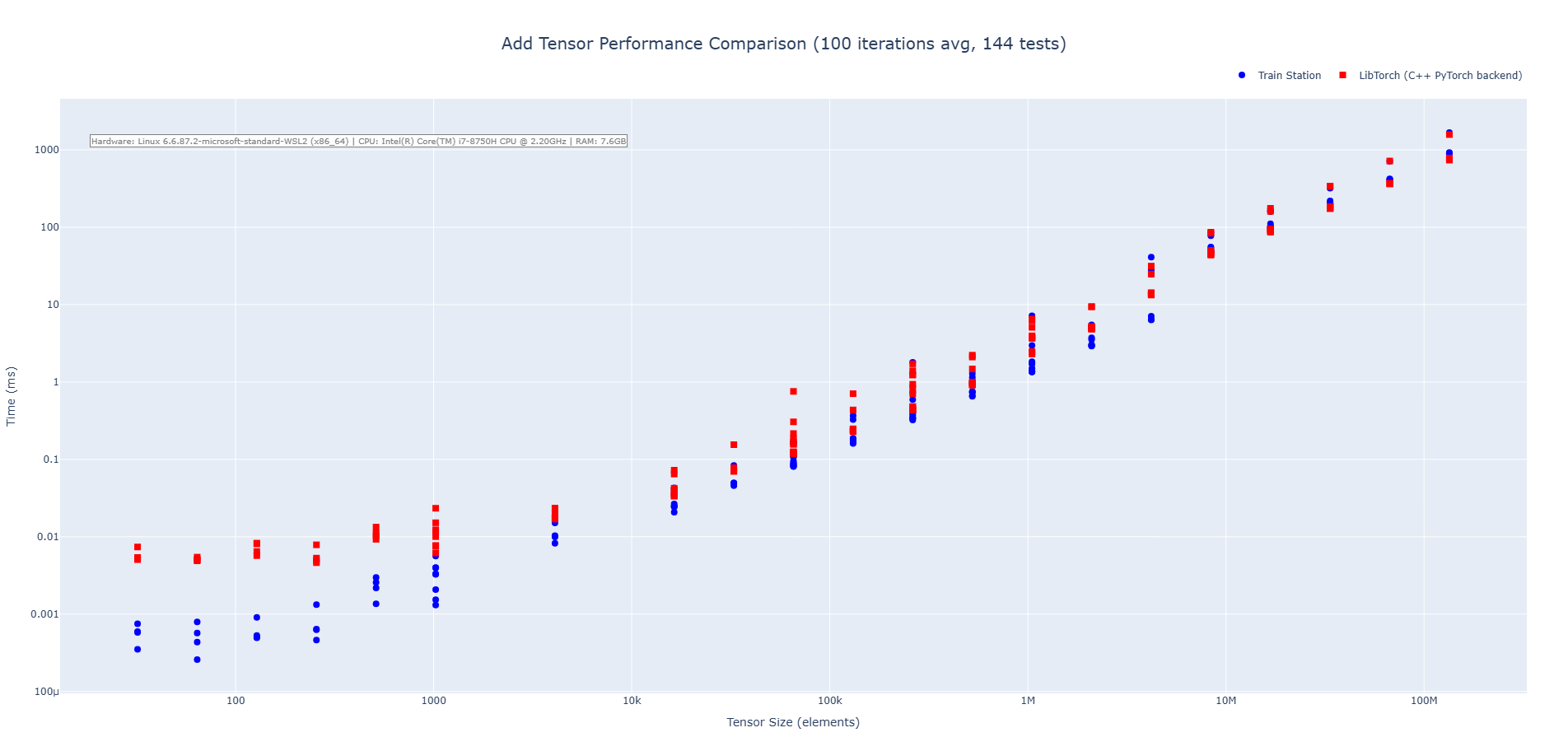
#### Subtraction
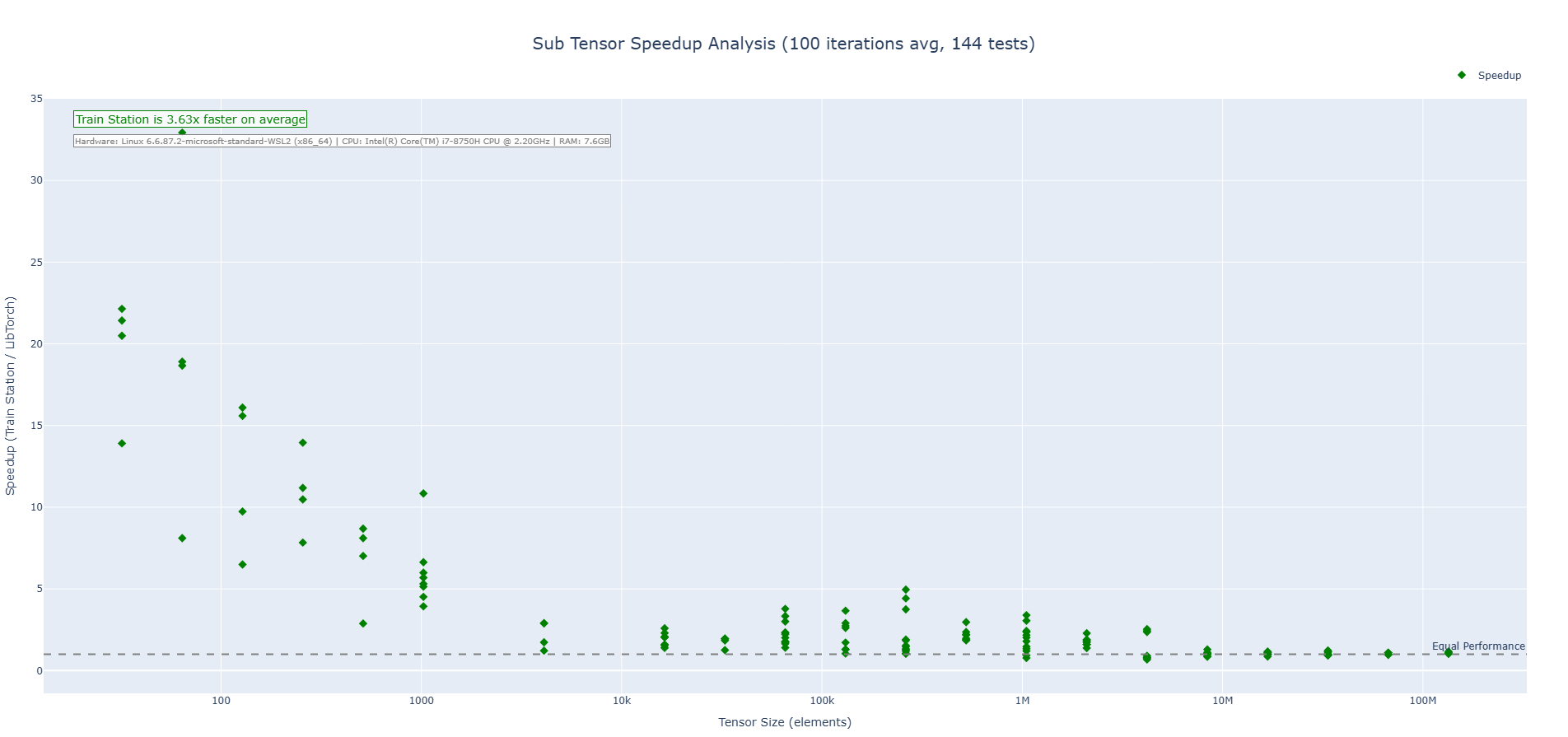
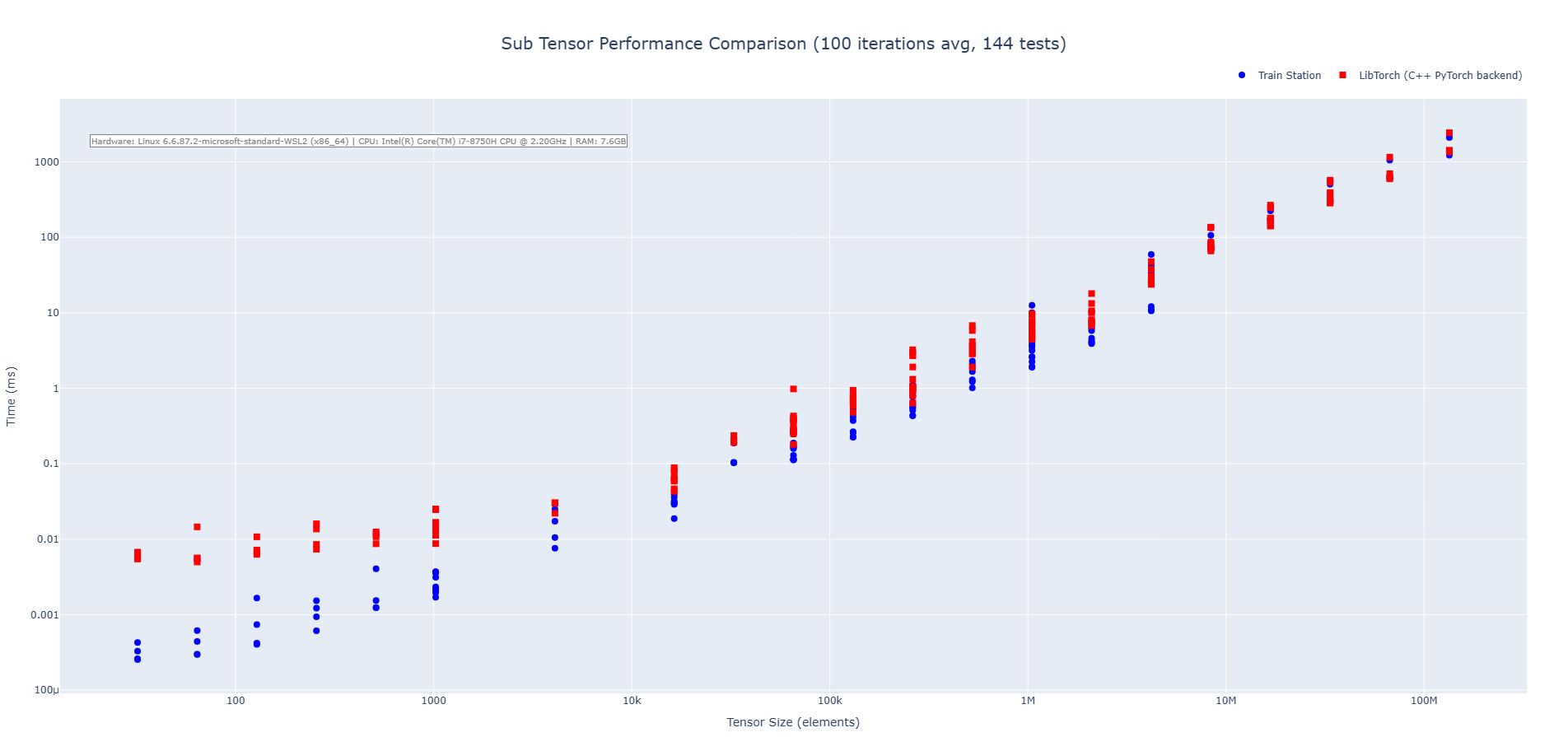
#### Multiplication
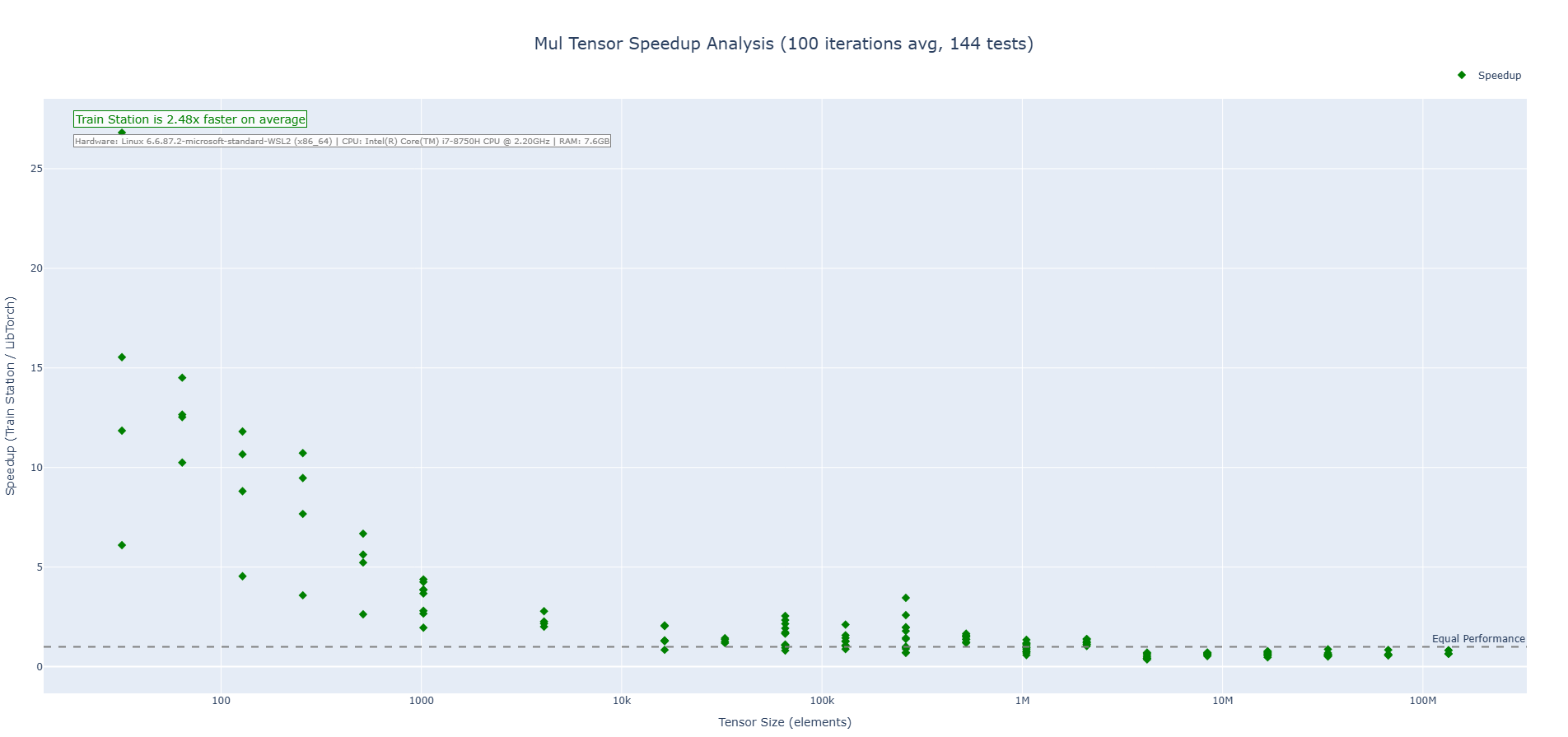
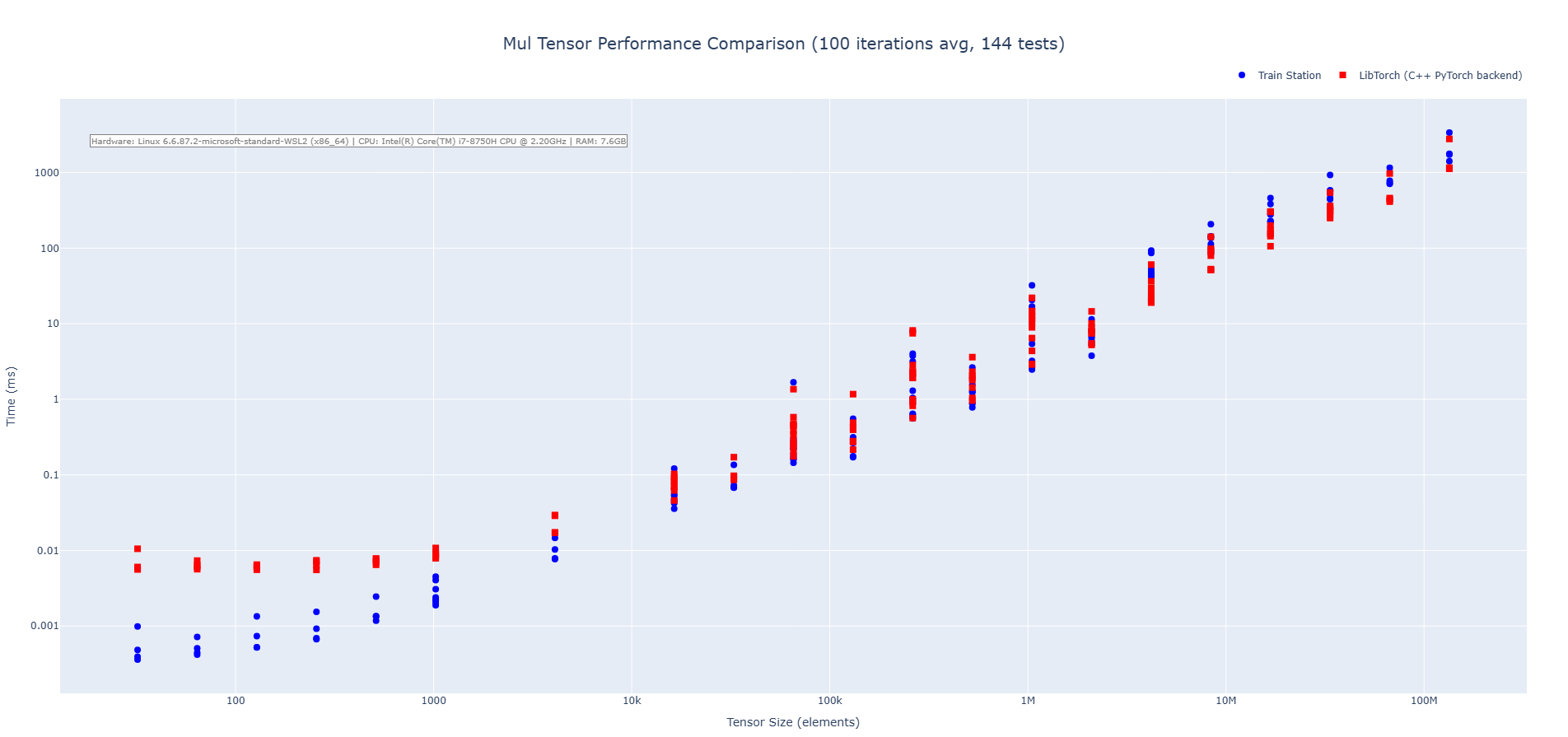
#### Division
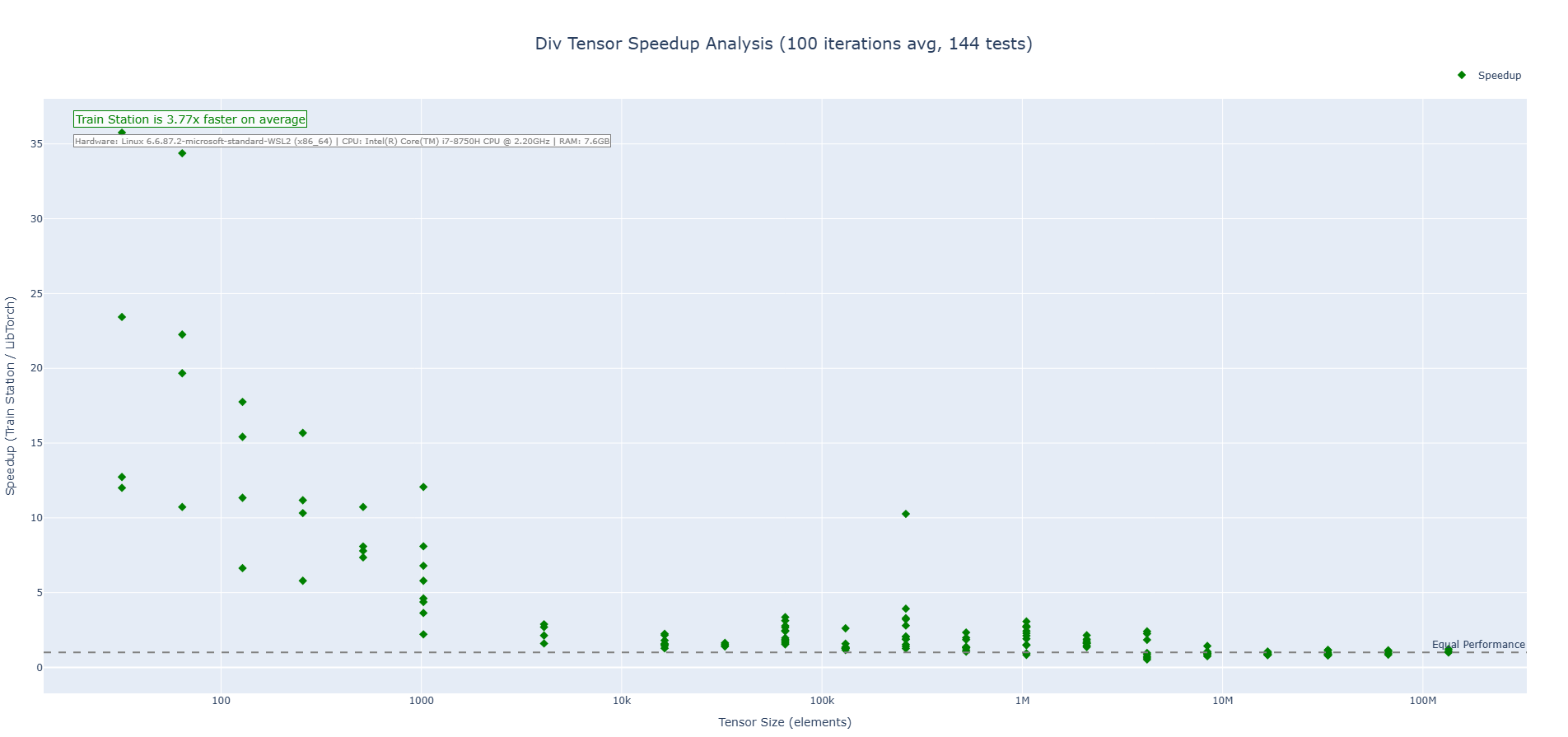
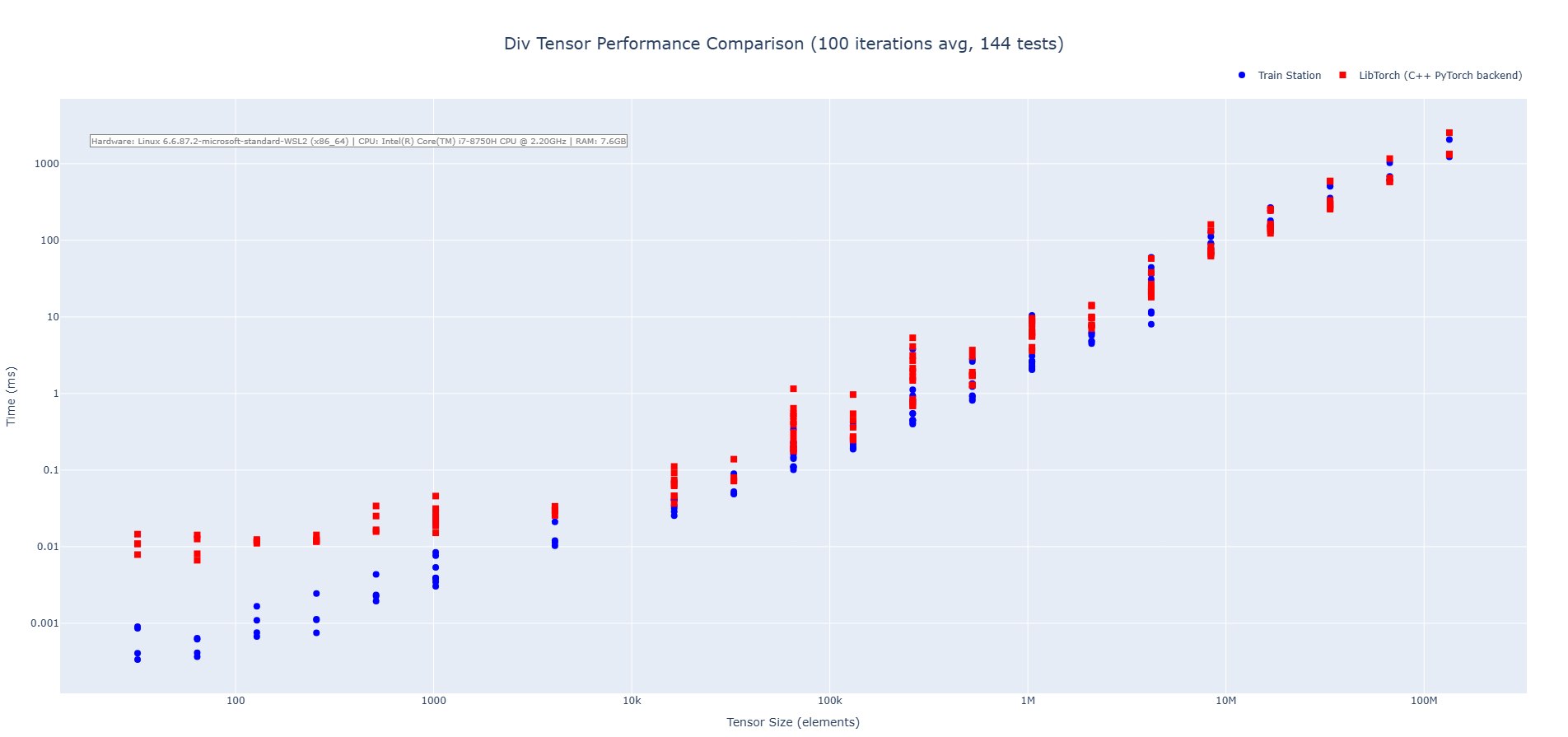
#### Matrix Multiplication
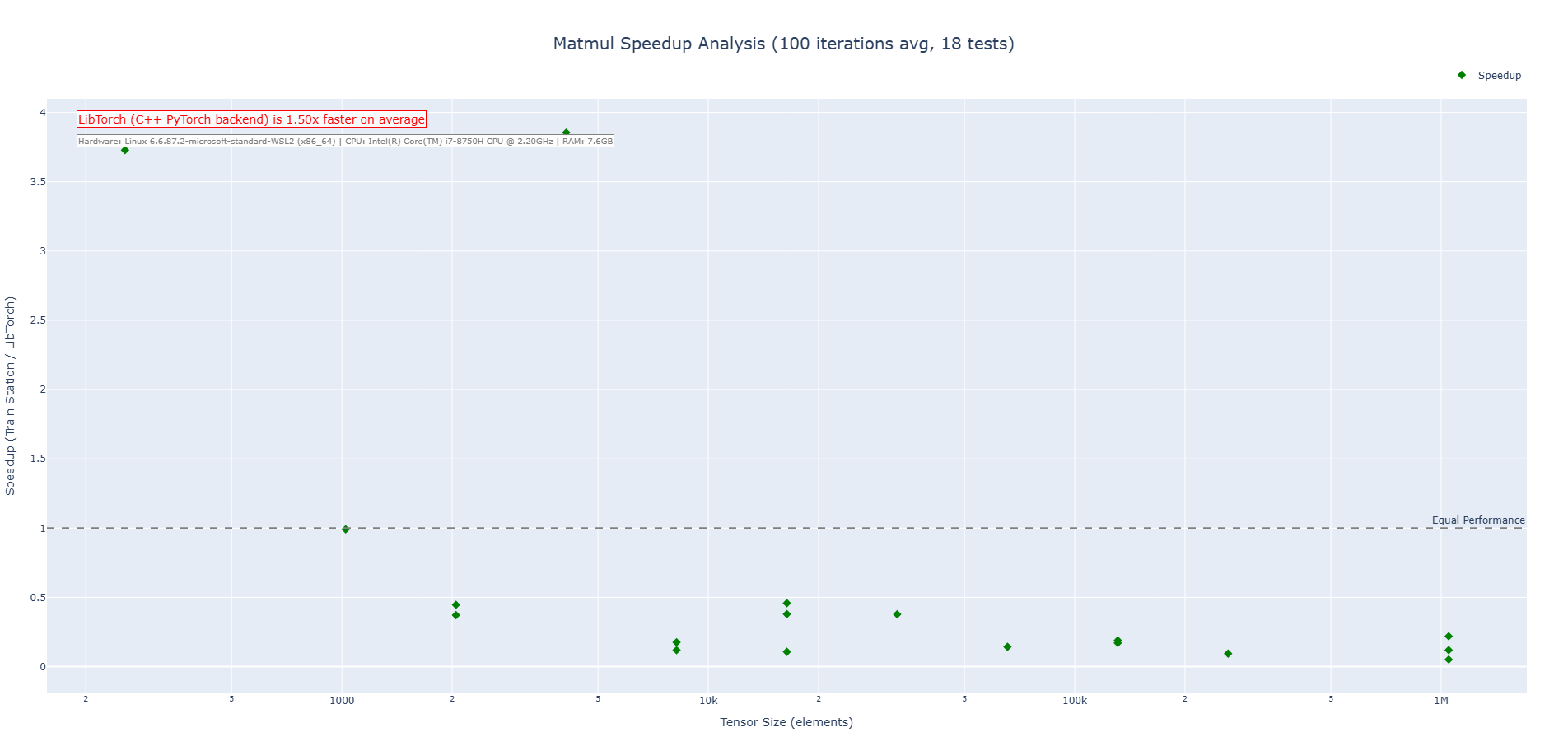
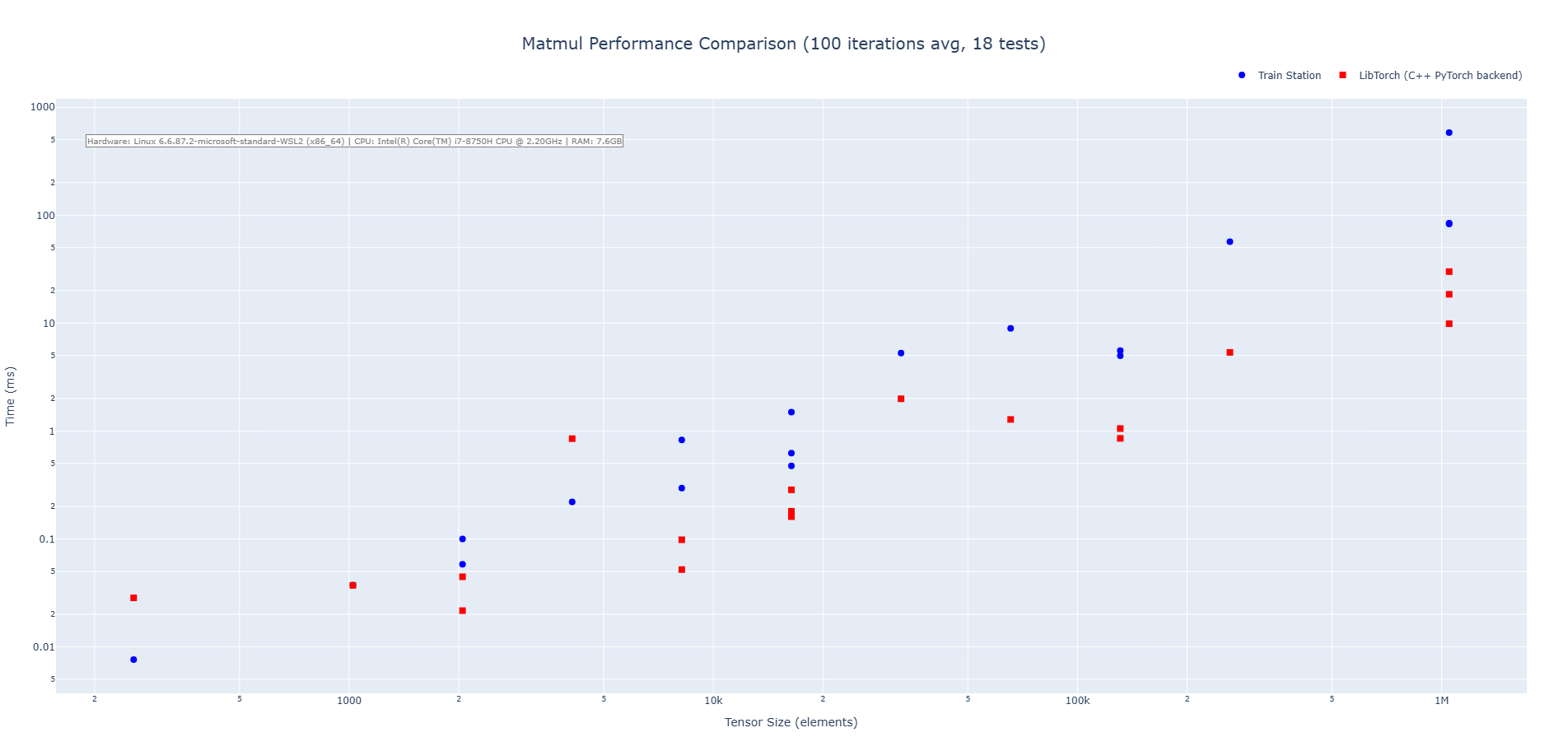
### Install & Platform Support
- Works on Linux, Windows, and macOS; x86_64 and ARM64 validated in CI.
- Add via Cargo:
```toml
[dependencies]
train-station = "0.2"
```
For detailed platform matrices, cross-compilation, and feature flags, see the original `README.md`.
### Links
- Crate: https://crates.io/crates/train-station
- Docs: https://docs.rs/train-station
- CI: see badges above
- Source: https://github.com/ewhinery8/train-station
#### CUDA Status
- The `cuda` feature is experimental and not ready for general use. It currently exposes scaffolding only; CPU is the supported path. Expect breaking changes while this area evolves.
### Roadmap
- Broaden core capabilities while staying zero-dependency and performance-first.
- Expand autograd coverage and iterator/view integrations across more operations.
- Evolve dtype support beyond `f32` while preserving ergonomics and speed.
- Grow the operation set and numerics needed for modern and next‑gen architectures.
- Mature training infrastructure (optimizers, serialization, reproducibility).
- Advance multi-threading and device support while keeping APIs simple and safe.
— Built for speed. Validated for correctness. Iterate faster.