# simd-normalizer
SIMD-accelerated Unicode normalization for Rust.
Provides NFC, NFD, NFKC, and NFKD normalization with a single-pass,
SIMD-guided architecture that scans 64-byte chunks to skip ASCII and
passthrough regions in bulk. Non-passthrough bytes are handled with scalar
decode, decompose, CCC sort, and optional recomposition. Tables are generated
from Unicode 17.0 data.
## Features
- **All four normalization forms** -- NFC, NFD, NFKC, NFKD
- **SIMD acceleration** -- x86_64 (SSE4.2 / AVX2 / AVX-512), aarch64 (NEON), wasm32 (simd128), with scalar fallback
- **Runtime CPU dispatch** on x86_64 with `std`; compile-time selection elsewhere
- **Zero-copy when possible** -- returns `Cow::Borrowed` when input is already normalized
- **Quick-check** -- `is_nfc()` / `is_nfd()` / `is_nfkc()` / `is_nfkd()` without allocating
- **Case folding** -- Unicode simple case folding (CaseFolding.txt C+S) with Turkish/Azerbaijani locale support
- **Confusable detection** -- UTS #39 skeleton algorithm and `are_confusable()` for anti-spoofing
- **Matching pipeline** -- fused NFKC + CaseFold + Confusable Skeleton for case-insensitive, confusable-aware string comparison
- **`no_std` compatible** -- core is `no_std + alloc`; enable the `std` feature for runtime dispatch
## Usage
Add to your `Cargo.toml`:
```toml
[dependencies]
simd-normalizer = "0.1"
```
### Normalization
```rust
use simd_normalizer::UnicodeNormalization;
let text = "e\u{0301}quipe"; // decomposed e-acute
let nfc = text.nfc(); // "équipe" (composed)
let nfd = text.nfd(); // "e\u{0301}quipe" (decomposed)
// Quick-check without allocation
assert!(nfc.is_nfc());
```
Or use the constructor API:
```rust
let normalizer = simd_normalizer::nfc();
let result = normalizer.normalize("cafe\u{0301}");
let is_nfc = normalizer.is_normalized("cafe\u{0301}");
```
### Case folding
```rust
use simd_normalizer::{casefold, CaseFoldMode};
let folded = casefold("Straße", CaseFoldMode::Standard);
assert_eq!(&*folded, "straße");
// Turkish locale: I -> ı (dotless i)
let turkish = casefold("Istanbul", CaseFoldMode::Turkish);
assert_eq!(&*turkish, "\u{0131}stanbul");
```
### Confusable detection
```rust
use simd_normalizer::{are_confusable, skeleton};
// Latin 'a' vs Cyrillic 'а' (U+0430)
assert!(are_confusable("apple", "\u{0430}\u{0440}\u{0440}le"));
// Get the confusable skeleton for a string
let skel = skeleton("paypal");
```
### Matching pipeline
```rust
use simd_normalizer::matching::{matches_normalized, MatchingOptions};
let opts = MatchingOptions::default();
// Case + confusable + compatibility equivalence in one step
assert!(matches_normalized("File", "file", &opts));
assert!(matches_normalized("a", "\u{0430}", &opts)); // Latin vs Cyrillic
assert!(matches_normalized("\u{FF21}", "a", &opts)); // Fullwidth A vs a
```
## Feature flags
| `std` | yes | Enables runtime CPUID dispatch on x86_64 |
| `alloc` | yes | Required for `String`/`Cow` return types |
| `quick_check_oracle` | no | Exposes a pre-classifier oracle slow path for differential testing. Internal only; semver-exempt. |
To use in `no_std`:
```toml
[dependencies]
simd-normalizer = { version = "0.1", default-features = false, features = ["alloc"] }
```
## SIMD backends
| x86_64 + `std` | SSE4.2 / AVX2 / AVX-512 | Runtime CPUID detection |
| x86_64 + `no_std` | Best available | Compile-time `target_feature` |
| aarch64 | NEON | Always (mandatory in AArch64) |
| wasm32 | simd128 | Compile-time feature flag |
| Other | Scalar | Automatic fallback |
Each backend processes 64-byte chunks using a vtable-dispatched scanner.
The scanner returns a 64-bit bitmask marking bytes that need scalar
processing; all-clear chunks are copied through with no per-byte work.
## Testing
The test suite includes 650+ tests across multiple categories:
- **UAX #15 conformance** -- full NormalizationTest.txt with all 20 invariants
- **Differential fuzzing** -- proptest against `unicode-normalization` and `icu_normalizer` (ICU4X) with thousands of generated inputs per form
- **Quick-check fast path vs oracle** -- 32K proptest cases per form compare the production quick-check against an in-tree slow-path oracle (enable `--features quick_check_oracle`)
- **Exhaustive codepoint validation** -- every Unicode scalar value tested for normalization invariants and differential correctness against ICU4X
- **Multilingual corpus** -- normalization verified on real-world text in 25+ languages (Arabic, Chinese, German, Greek, Hebrew, Hindi, Japanese, Korean, Russian, Thai, Turkish, and more)
- **SIMD boundary stress** -- multi-byte sequences straddling 64-byte chunk boundaries
- **Edge cases** -- Hangul Jamo composition, CCC reordering, composition exclusions, orphan combining marks, supplementary characters, >32 combining marks
- **Case folding and confusables** -- BMP/supplementary exhaustive idempotence, Turkish locale, skeleton convergence, Latin/Cyrillic/Greek homoglyph pairs
```sh
cargo test # Run all tests
cargo test -- --ignored # Run exhaustive tests (slow, ~1.1M codepoints x 4 forms)
```
## Benchmarks
```sh
cargo bench
```
Benchmarks compare throughput against `icu_normalizer` (ICU4X) and
`unicode-normalization` across nine input categories (ASCII, Latin-1, CJK,
Arabic, Hangul, emoji, mixed-script, already-normalized, and worst-case)
using [Criterion](https://github.com/bheisler/criterion.rs). Results are
reported as bytes/second throughput.
## Performance
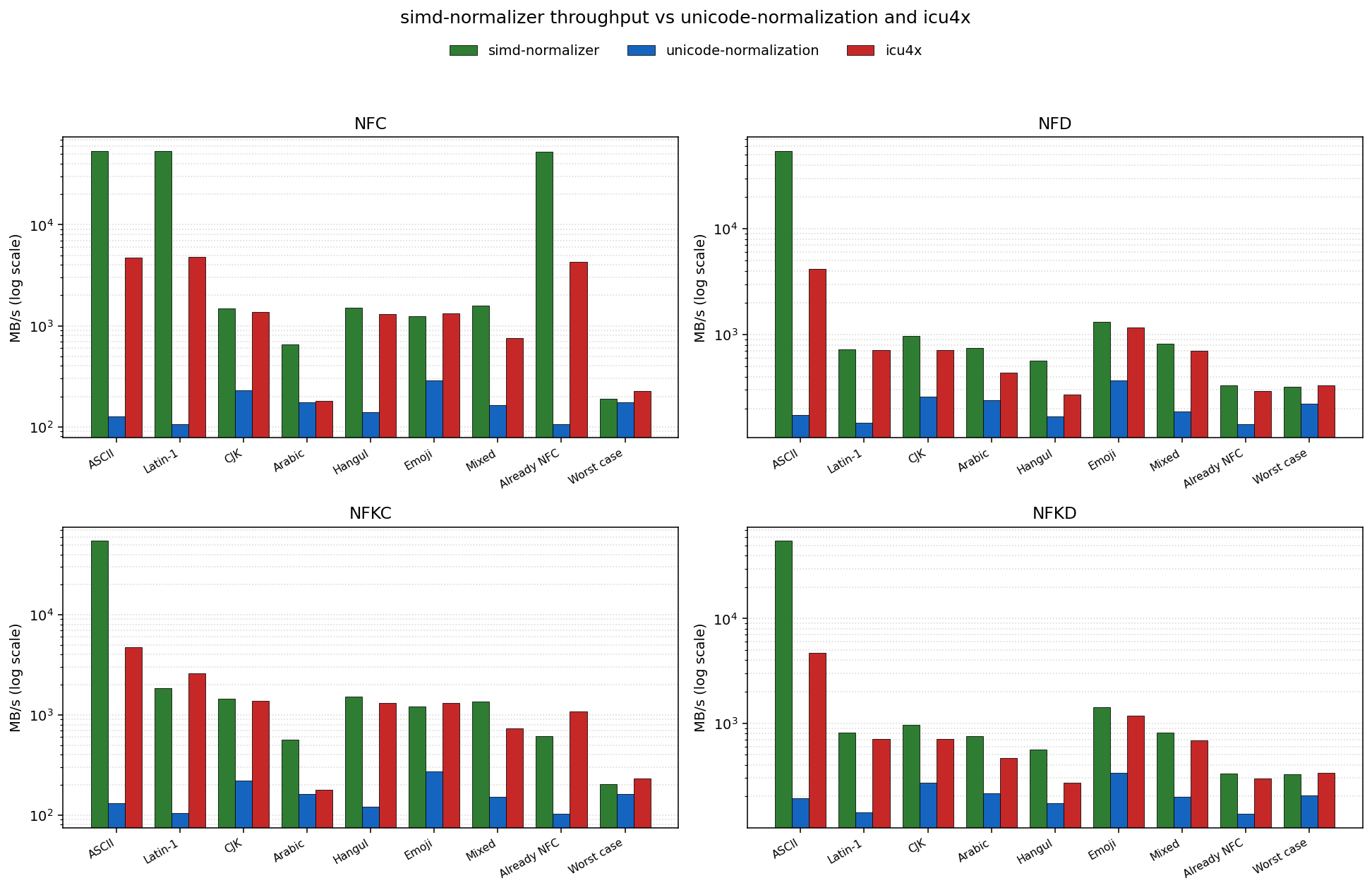
Measured on an AMD Ryzen AI 9 HX PRO 370 (Zen 5, AVX2) with `rustc 1.95.0`
on Linux x86_64, using the Criterion bench suite in `benches/bench.rs`.
The SIMD scanner copies all-ASCII and passthrough chunks in bulk, so
`simd-normalizer` pulls ahead dramatically on ASCII / Latin-1 / already-NFC
inputs; on dense combining-mark or CJK inputs the per-codepoint scalar path
dominates and throughput lands in the same order of magnitude as ICU4X.
Regenerate the chart with `cargo bench && python3 scripts/plot_throughput.py`.
## License
Licensed under the Apache License, Version 2.0 ([LICENSE](LICENSE) or
<http://www.apache.org/licenses/LICENSE-2.0>).