
.__ .__ __ .__ .__ .__
│__│______│__│╱ │_│ │__ ___.__.│ │ │ │
│ ╲_ __ ╲ ╲ __╲ │ < │ ││ │ │ │
│ ││ │ ╲╱ ││ │ │ Y ╲___ ││ │_│ │__
│__││__│ │__││__│ │___│ ╱ ____││____╱____╱
╲╱╲╱

![]()
![]()

![]()

Streaming machine learning in Rust. Gradient-boosted trees, neural streaming architectures, kernel methods, and linear models all behind a single StreamingLearner trait. One sample at a time. O(1) memory.
What it is
irithyll is a streaming ML library for the case where data arrives in order and never stops. There is no training set. There is no batch loop. Every sample updates the model and is then released without buffering or replay. Trees, state-space models, kernels, attention, and spiking networks all expose the same two-method interface: train_one(features, target, weight) and predict(features) -> f64. A Box<dyn StreamingLearner> is a fully typed model.
The workspace splits into two crates: irithyll (the full library, std) and irithyll-core (a no_std subset that handles its share of the streaming models and the packed inference format). The Bare-Metal Deployment section below covers the embedded path.
It is a deliberate library. Every threshold derives from a paper. Every neural readout is bounded before it touches the linear head. Every config field round-trips through a builder that validates rather than accepts. Where the literature gives an option, the option becomes a feature flag, not a default.
It serves online forecasting under concept drift, research benches where new streaming architectures land next to SGBT and are held to the same throughput and accuracy floor, edge inference at sample rate, and embedded learning where the dataset would never fit in RAM.
Quick Start
Four snippets, in order of how a streaming pipeline grows.
The smallest useful thing -- normalize, boost, predict.
use ;
let mut model = pipe.learner;
model.train;
let pred = model.predict;
Race three model families against each other -- let the data choose.
use ;
let mut tuner = builder
.add_factory
.add_factory
.add_factory
.use_drift_rerace
.build;
tuner.train;
let pred = tuner.predict;
Mix architectures inside a single mixture-of-experts -- heterogeneous experts welcome.
use ;
let mut moe = builder
.expert
.expert_with_warmup
.top_k
.build;
Turn any regressor into a classifier -- binary_classifier and multiclass_classifier wrap a StreamingLearner with bipolar one-vs-rest heads.
use ;
let mut clf = binary_classifier;
clf.train; // labels are 0.0 / 1.0
let prob_positive = clf.predict;
Composition is the point. Anything that implements StreamingLearner slots into a pipeline, an MoE expert, an AutoML candidate, a projection wrapper, or a classification head. The trait is the contract; the rest is LEGO.
For the longer ergonomics story -- pipeline composition, AutoML tournaments, drift wiring, embedded deployment -- see docs/USAGE.md.
Design Principles
The library has opinions. They are stable across releases and they shape every model.
Streaming is total. Every sample triggers a complete forward and backward step and is then released; a single pass through the data is the only pass. Architectures originally designed for offline training -- TTT, KAN, Mamba -- are reimplemented with online updates that converge sample-by-sample. Memory follows the model, not the stream: a million samples and a billion samples occupy the same number of bytes, because drift detectors are bounded ring buffers, histograms carry fixed bin counts, and subspace trackers hold a rank-k projection.
Bounded readouts before linear heads. Every neural model feeding a recursive least squares head bounds its features first with tanh, sigmoid, L2-normalization, or clamping. This prevents feature explosion in the RLS head and is required for all new neural architectures.
Constants from theory, self-calibration otherwise. Bernstein bounds for promotion tests, the Hoeffding inequality for split decisions, the PAST update for streaming PCA. Where a paper provides a constant, the constant cites the paper. Where theory is silent, online statistics self-calibrate rather than relying on magic numbers.
Validation by builder. Every public Config carries a Builder returning Result<_, ConfigError>. Bounds are checked before construction; impossible configurations cannot be created.
Safety is structural. irithyll carries #![forbid(unsafe_code)] at the crate root, so the entire training surface is safe Rust by construction. irithyll-core uses localized unsafe for zero-copy view parsing of the packed binary format and AVX2 SIMD intrinsics (behind the simd-avx2 feature), each with documented preconditions.
Workspace
| Crate | What it does | no_std |
|---|---|---|
irithyll |
Training, streaming algorithms, pipelines, async I/O, AutoML | No |
irithyll-core |
no_std streaming training + packed inference -- Mamba-3, LLA, SNN, drift detectors, primitives, 12-byte tree format |
Yes |
irithyll-python |
PyO3 bindings for AutoTuner, ProjectedLearner, and factory variants |
No |
irithyll-core cross-compiles for bare-metal targets including thumbv6m-none-eabi (Cortex-M0+), thumbv7m-none-eabi (M3), and thumbv7em-none-eabi (M4). All are tested in CI. Its only dependency is libm for soft-float math; everything else (SIMD, parallel, serde) is opt-in. Train with the full crate, export to packed format, run inference on the microcontroller with identical predictions.
Models and Architecture
Every model in irithyll is streaming-trainable end-to-end; there is no inference-only tier. Every model implements StreamingLearner, and every neural readout is bounded before it reaches a recursive least squares head -- a structural rule, not a per-model decision. The four columns below group families by what they are, not by maturity.
| Family | Members |
|---|---|
| Trees & classical | SGBT family (SGBT, DistributionalSGBT, BaggedSGBT, MulticlassSGBT, ParallelSGBT), RecursiveLeastSquares, KRLS, Mondrian forests, Hoeffding trees, Gaussian Naive Bayes, linear / polynomial models |
| Neural | Mamba family (V1 / V3 / Mamba-3), Echo State Networks, Next-Gen Reservoir Computing, StreamingTTT, StreamingKAN / T-KAN, AGMP, mGRADE, HGRN2, sLSTM, SpikeNet (e-prop + surrogate gradients), StreamingAttentionModel (12 attention modes including Log-Linear) |
| Wrappers & inspection | Packed inference (irithyll-core), conformal prediction with PID control, anomaly detection, ProjectedLearner (online subspace tracking via PAST), TreeSHAP |
| Composition | NeuralMoE (heterogeneous experts, top-k routing, drift-aware), streaming AutoML (AutoTuner, tournament racing, drift re-racing, complexity-adjusted elimination) |
Classification works on top of regression: binary_classifier(model) and multiclass_classifier(model, k) wrap any StreamingLearner with bipolar one-vs-rest heads.
For per-model architecture, paper citations, when-to-use guidance, math summaries, and config references, see MODELS.md.
Tools and CLI
The irithyll command-line interface provides interactive training, evaluation, and inspection of streaming models on CSV data. The TUI (terminal user interface) offers live dashboards monitoring model state, drift events, and AutoML tournaments. Key commands:
irithyll train <csv>-- Train a model on a CSV file with live metrics.irithyll eval <csv>-- Evaluate an existing model on held-out data.irithyll --tui-- Launch the interactive dashboard (supports--model-typeand--benchflags).irithyll --family <name> --bench <dataset>-- Run built-in benchmarks (Friedman, Lorenz, Mackey-Glass, etc.).irithyll inspect <model>-- Examine model state, feature importance, and configuration.irithyll export <model>-- Export a trained model to packed binary format for embedded deployment.
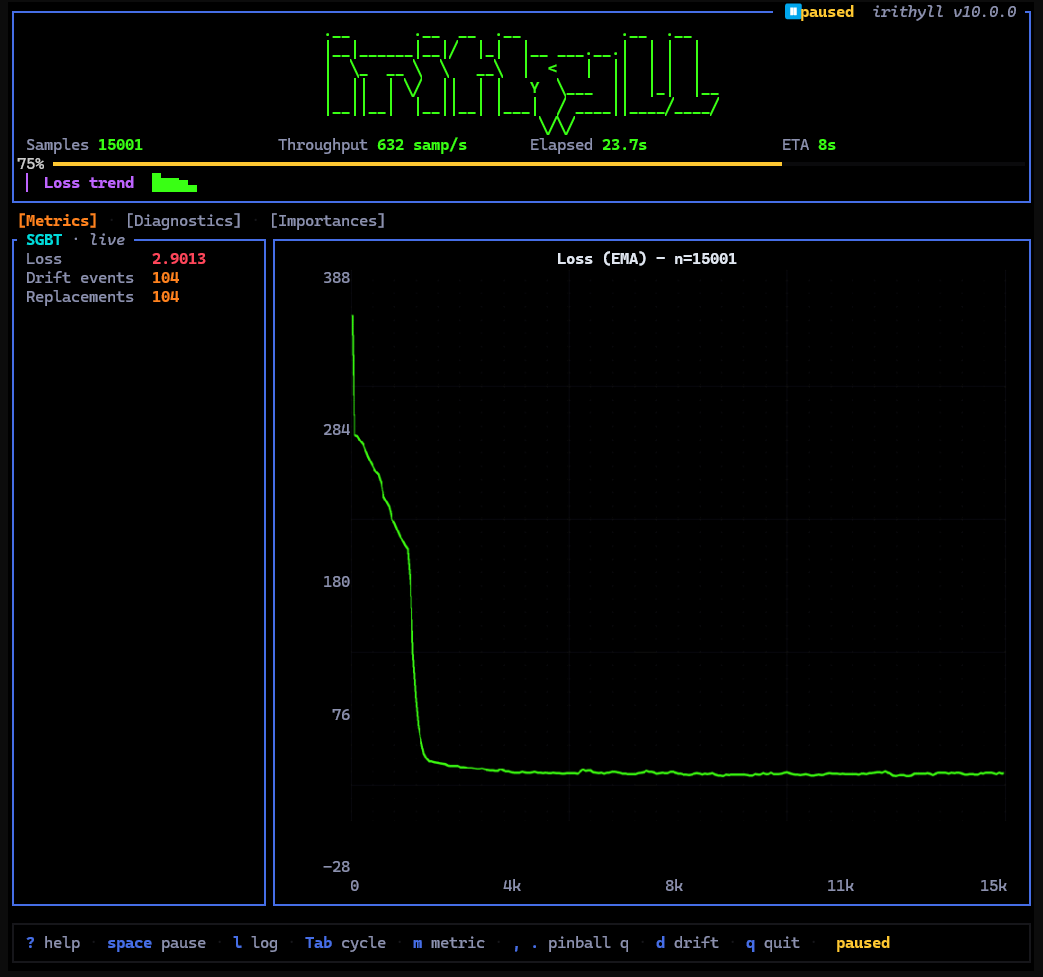
Live multi-family dashboard -- loss curve, per-family diagnostics, feature importance, drift markers.

Throttled for demo; native throughput finishes the 20k-sample stream in well under a second.
Built-in benchmarks: friedman, lorenz, mackey-glass, periodic, mqar, needle. Supported families: sgbt, mamba, ttt, kan, esn, ngrc, spike-net. Per-feature importance is available for SGBT, KAN, and Linear models.
Drift Handling
The world distribution shifts. Streaming models that don't notice lie. irithyll treats drift as a first-class signal, not a recovery story.
Three detectors ship in irithyll::drift: ADWIN (Bifet & Gavaldà 2007) for adaptive windowing, DDM (Gama et al. 2004) for the warning-and-drift two-stage state machine, and Page-Hinkley for cumulative-deviation tests. They expose a single update(error) -> DriftState interface, plug into any model that takes a Box<dyn DriftDetector>, and respond to adjust_config() calls when AutoML wants to widen the learning rate during a re-race.
Inside SGBT, drift drives tree replacement. Each boosting stage carries a detector watching its standardized residual. When drift fires, that stage's tree is replaced with a fresh alternate that warms up in parallel before promotion. The ensemble keeps predicting throughout without rebuild pause.
Inside AutoML, drift drives re-racing. The AutoTuner re-evaluates challenger configurations against the champion when the residual distribution shifts, with the comparison gated by an empirical Bernstein promotion test (bernstein_promotion_test in automl::racing). The champion never flips on noise.
Bare-Metal Deployment
The packed inference path is a deliberate boundary. Train with the full crate, export to a 12-byte-per-node binary representation, deserialize on a microcontroller in pure #![no_std] without an allocator, and predict.
// On the host: train, then export to packed bytes.
use ;
use export_packed;
let mut model = SGBTnew;
// ... train on a stream ...
let packed_bytes: = export_packed;
// Write to flash, ship to device.
// On the device: zero-copy view over the bytes. No std, no allocation in predict.
use EnsembleView;
let view = from_bytes.unwrap;
let prediction: f32 = view.predict;
Validation happens once in from_bytes (magic bytes, child-index bounds, feature-index bounds); after that, prediction is pure pointer arithmetic. Five nodes fit per 64-byte cache line, learning rate is baked into leaf values at export time, and an 8-byte int16-quantized variant (export_packed_i16 + QuantizedEnsembleView) eliminates floats from the inference hot loop entirely. The crate's only dependency is libm. CI cross-compiles for all three Cortex-M targets on every commit.
Feature Flags
irithyll-core's default build is pure no_std with no allocator and no std, just libm for soft-float math. Opt-in features (alloc, std, serde, simd, simd-avx2, parallel) extend it as needed. The device-side inference path on the previous page runs in the strictest mode. Neural streaming modules in the main crate compile unconditionally without flags.
| Feature | Default | Description |
|---|---|---|
serde-json |
Yes | JSON model serialization |
serde-bincode |
No | Compact binary serialization |
parallel |
No | Rayon-based parallel tree training (ParallelSGBT) |
simd |
No | Generic SIMD acceleration |
simd-avx2 |
No | AVX2 histogram + neural ops (x86_64 only) |
kmeans-binning |
No | K-means histogram binning strategy |
arrow |
No | Apache Arrow RecordBatch integration |
parquet |
No | Parquet file I/O |
onnx |
No | ONNX model export |
neural-leaves |
No | Experimental MLP leaf models |
full |
No | Everything above |
References
The implementations cite their sources. The list below is the load-bearing core of papers whose math directly shapes models in irithyll. The complete bibliography (foundations, related work, surveys) lives in REFERENCES.md.
Streaming Boosting and Trees
- Gunasekara, Pfahringer, Gomes, Bifet (2024). Gradient boosted trees for evolving data streams. Machine Learning, 113, 3325-3352.
- Domingos, Hulten (2000). Mining high-speed data streams. KDD 2000. -- Hoeffding bound for online splits.
- Bifet, Gavaldà (2007). Learning from time-changing data with adaptive windowing. SIAM SDM 2007. -- ADWIN.
- Lundberg et al. (2020). From local explanations to global understanding with explainable AI for trees. Nature Machine Intelligence, 2, 56-67. -- TreeSHAP.
State-Space Models and Recurrent Networks
- Gu, Dao (2023). Mamba: Linear-time sequence modeling with selective state spaces. arXiv:2312.00752.
- Dao, Gu (2024). Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. arXiv:2405.21060.
- Gu, Gupta, Goel, Ré (2022). On the parameterization and initialization of diagonal state space models. NeurIPS 2022. -- S4D-Inv.
- Beck et al. (2024). xLSTM: Extended long short-term memory. NeurIPS 2024. -- mLSTM / sLSTM.
Streaming Linear Attention
- Yang, Wang, Shen, Panda, Kim (2023). Gated linear attention transformers with hardware-efficient training. arXiv:2312.06635. -- GLA.
- Yang et al. (2024). Gated Delta Networks: Improving Mamba2 with Delta Rule. arXiv:2412.06464. -- DeltaNet / GatedDeltaNet.
- Sun et al. (2023). Retentive network: A successor to transformer for large language models. arXiv:2307.08621. -- RetNet.
- De et al. (2024). Griffin: Mixing gated linear recurrences with local attention. arXiv:2402.19427. -- Hawk.
- Peng et al. (2024). Eagle and Finch: RWKV with matrix-valued states and dynamic recurrence. arXiv:2404.05892. -- RWKV.
Test-Time Training, KAN, Reservoir, Spiking
- Sun et al. (2024). Learning to (Learn at Test Time): RNNs with expressive hidden states. ICML 2025. -- StreamingTTT.
- Behrouz, Zhong, Mirrokni (2025). Titans: Learning to memorize at test time. arXiv:2501.00663. -- momentum + weight-decay TTT.
- Liu et al. (2024). KAN: Kolmogorov-Arnold Networks. ICLR 2025.
- Hoang et al. (2026). Ultrafast on-chip online learning via Kolmogorov-Arnold Networks. arXiv:2602.02056. -- streaming convergence.
- Gauthier, Bollt, Griffith, Barbosa (2021). Next generation reservoir computing. Nature Communications, 12, 5564.
- Rodan, Tiňo (2010). Minimum complexity echo state network. IEEE TNN, 23(1).
- Bellec et al. (2020). A solution to the learning dilemma for recurrent networks of spiking neurons. Nature Communications, 11, 3625. -- e-prop.
Mixture-of-Experts and AutoML
- Shazeer et al. (2017). Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. ICLR 2017.
- Aspis et al. (2025). DriftMoE: Mixture of experts for streaming classification with concept drift. ECMLPKDD 2025.
- Wu, Iyer, Wang (2021). ChaCha for online AutoML. ICML 2021.
- Qi et al. (2023). Discounted Thompson Sampling for non-stationary bandits. arXiv:2305.10718.
Continual Learning, Conformal, Projection
- Dohare et al. (2024). Loss of plasticity in deep continual learning. Nature, 632, 768-774.
- Kirkpatrick et al. (2017). Overcoming catastrophic forgetting in neural networks. PNAS, 114(13). -- EWC.
- Angelopoulos, Candes, Tibshirani (2023). Conformal PID control for time series prediction. NeurIPS 2023.
- Yang (1995). Projection approximation subspace tracking. IEEE TSP, 43(1). -- PAST.
Further Reading
| Document | Contents |
|---|---|
MODELS.md |
Per-model architecture, paper citation, when-to-use, math summary, config reference |
docs/USAGE.md |
Extended ergonomics -- pipelines, AutoML, MoE composition, embedded deployment |
BENCHMARKS.md |
Benchmark methodology, datasets, throughput numbers, Pareto plots |
REFERENCES.md |
Complete bibliography, organized by tier |
examples/ |
Runnable examples, organized 01_quickstart → 02_essentials → 03_neural → 04_advanced |
CHANGELOG.md |
Release history |
CONTRIBUTING.md |
Contribution guide and code standards |
| docs.rs | Full API reference |
License
Licensed under either of
- Apache License, Version 2.0 (LICENSE-APACHE or http://www.apache.org/licenses/LICENSE-2.0)
- MIT License (LICENSE-MIT or http://opensource.org/licenses/MIT)
at your option.
Unless you explicitly state otherwise, any contribution intentionally submitted for inclusion in this work by you, as defined in the Apache-2.0 license, shall be dual licensed as above, without any additional terms or conditions.
MSRV: 1.75. Checked in CI; raised only in minor version bumps.