# dataprof
[](https://github.com/AndreaBozzo/dataprof/actions)
[](LICENSE)
[](https://www.rust-lang.org)
[](https://crates.io/crates/dataprof)
[](https://pepy.tech/projects/dataprof)
A fast, reliable data quality assessment tool built in Rust. Analyze datasets with 20x better memory efficiency than pandas, unlimited file streaming, and comprehensive ISO 8000/25012 compliant quality checks across 5 dimensions: Completeness, Consistency, Uniqueness, Accuracy, and Timeliness. Full Python bindings and production database connectivity included.
Perfect for data scientists, engineers, analysts, and anyone working with data who needs quick, reliable quality insights.
## Privacy & Transparency
DataProf processes **all data locally** on your machine. Zero telemetry, zero external data transmission.
**[Read exactly what DataProf analyzes →](docs/WHAT_DATAPROF_DOES.md)**
- 100% local processing - your data never leaves your machine
- No telemetry or tracking
- Open source & fully auditable
- Read-only database access (when using DB features)
**Complete transparency:** Every metric, calculation, and data point is documented with source code references for independent verification.
## CI/CD Integration
Automate data quality checks in your workflows with our GitHub Action:
```yaml
- name: DataProf Quality Check
uses: AndreaBozzo/dataprof-actions@v1
with:
file: 'data/dataset.csv'
quality-threshold: 80
fail-on-issues: true
# Batch mode (NEW)
recursive: true
output-html: 'quality-report.html'
```
**[Get the Action →](https://github.com/AndreaBozzo/dataprof-action)**
- **Zero setup** - works out of the box
- **ISO 8000/25012 compliant** - industry-standard quality metrics
- **Batch processing** - analyze entire directories recursively
- **Flexible** - customizable thresholds and output formats
- **Fast** - typically completes in under 2 minutes
Perfect for ensuring data quality in pipelines, validating data integrity, or generating automated quality reports.Updated to latest release.
## Quick Start
### CLI (Recommended - Full Features)
> **Installation**: Download pre-built binaries from [Releases](https://github.com/AndreaBozzo/dataprof/releases) or build from source with `cargo install dataprof`.
> **Note**: After building with `cargo build --release`, the binary is located at `target/release/dataprof-cli.exe` (Windows) or `target/release/dataprof` (Linux/Mac). Run it from the project root as `target/release/dataprof-cli.exe <command>` or add it to your PATH.
#### Basic Analysis
```bash
# Comprehensive quality analysis
dataprof analyze data.csv --detailed
# Analyze Parquet files (requires --features parquet)
dataprof analyze data.parquet --detailed
# Windows example (from project root after cargo build --release)
target\release\dataprof-cli.exe analyze data.csv --detailed
```
#### HTML Reports
```bash
# Generate HTML report with visualizations
dataprof report data.csv -o quality_report.html
# Custom template
dataprof report data.csv --template custom.hbs --detailed
```
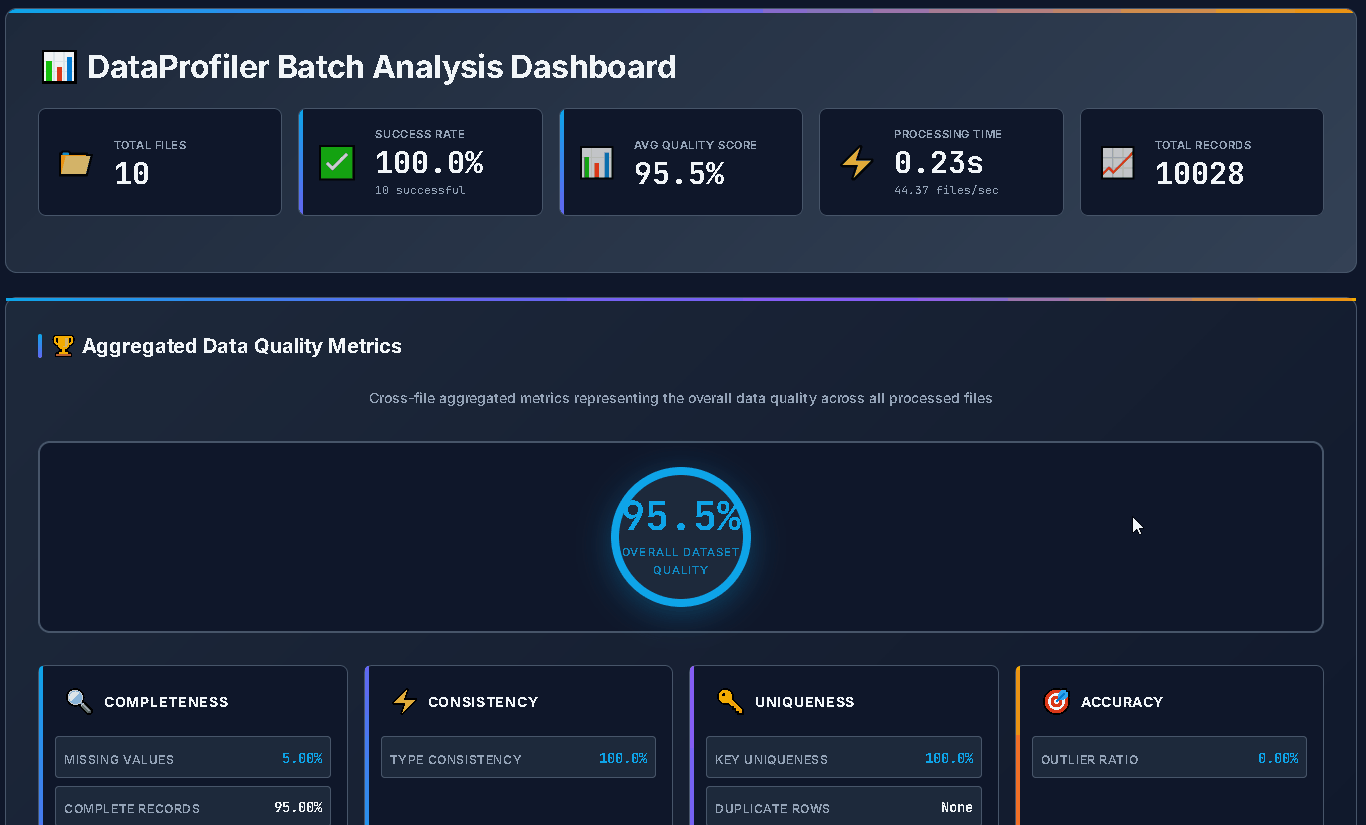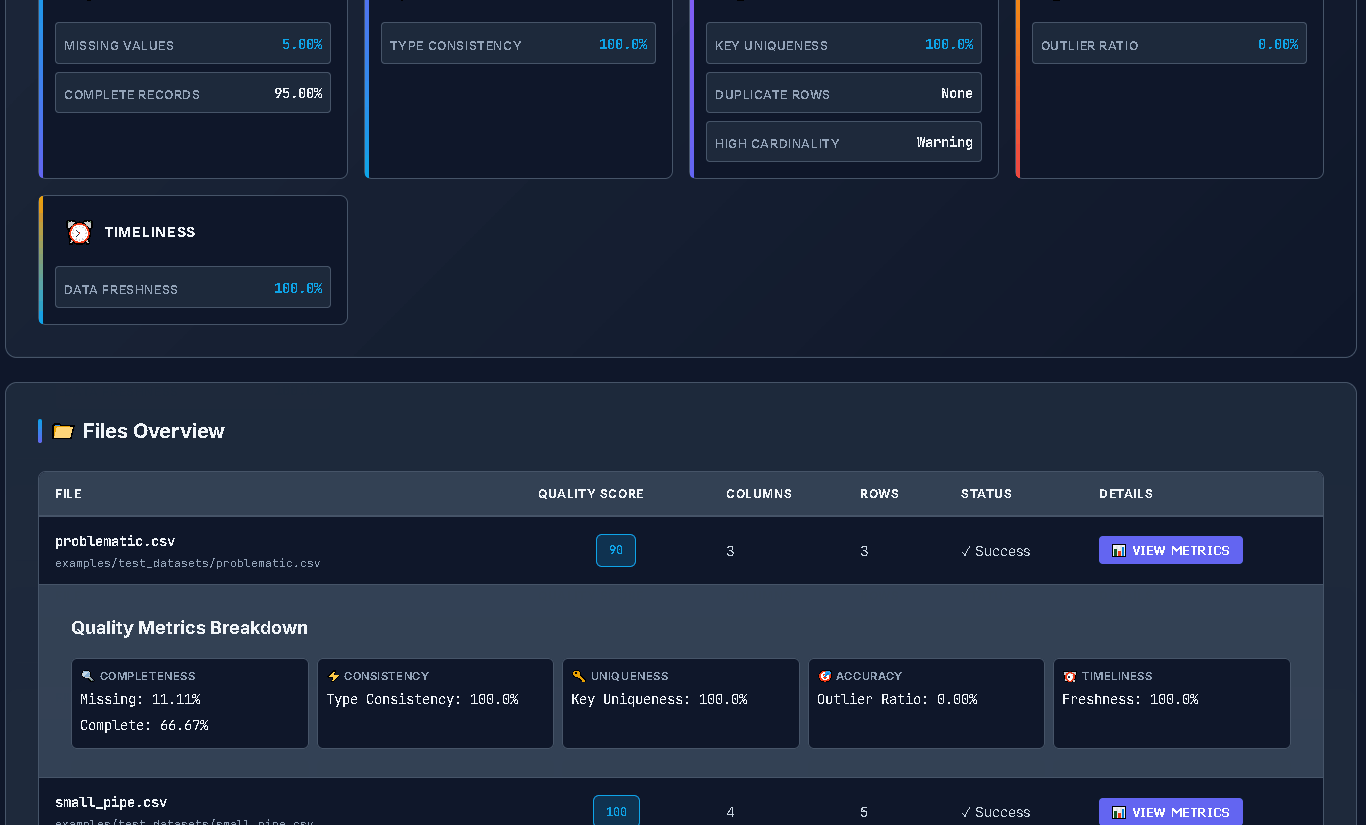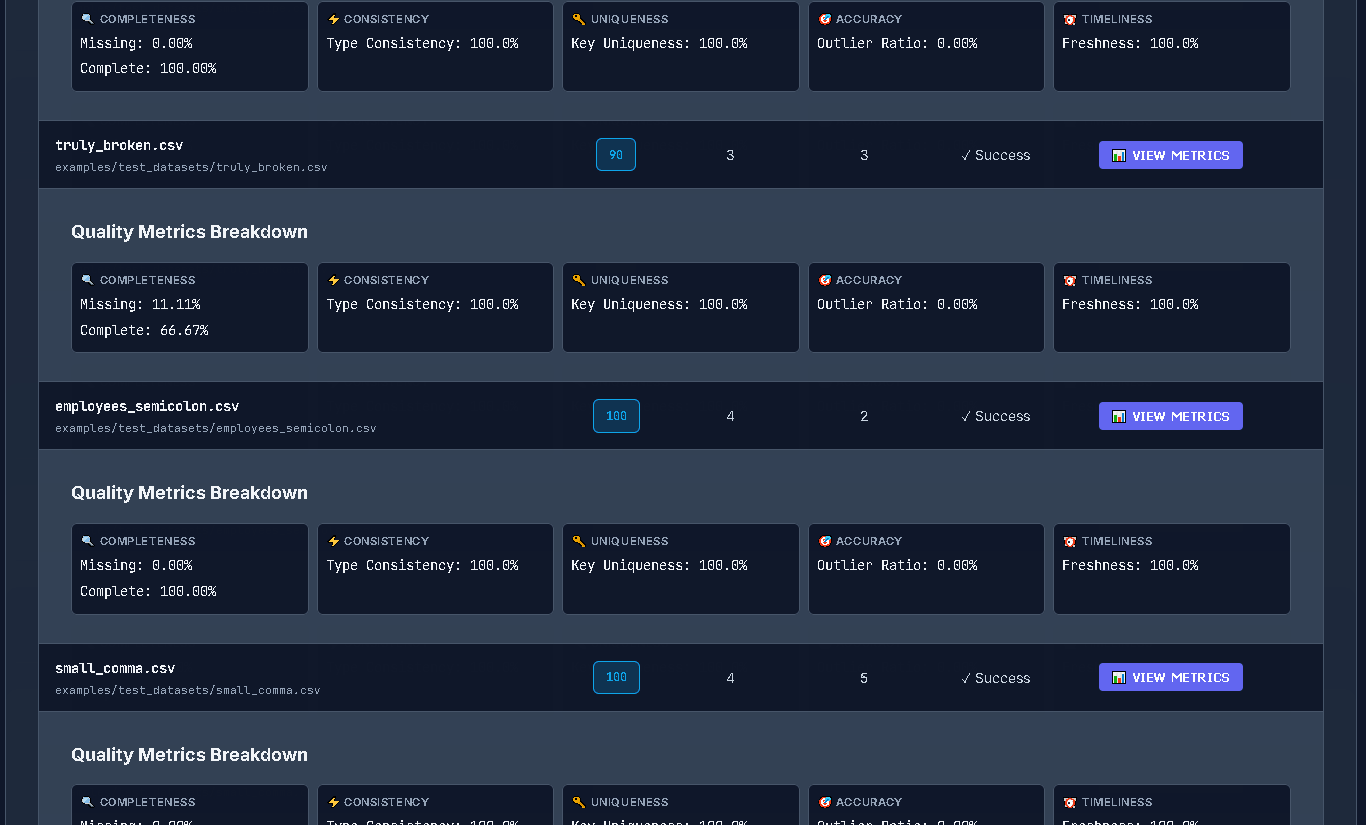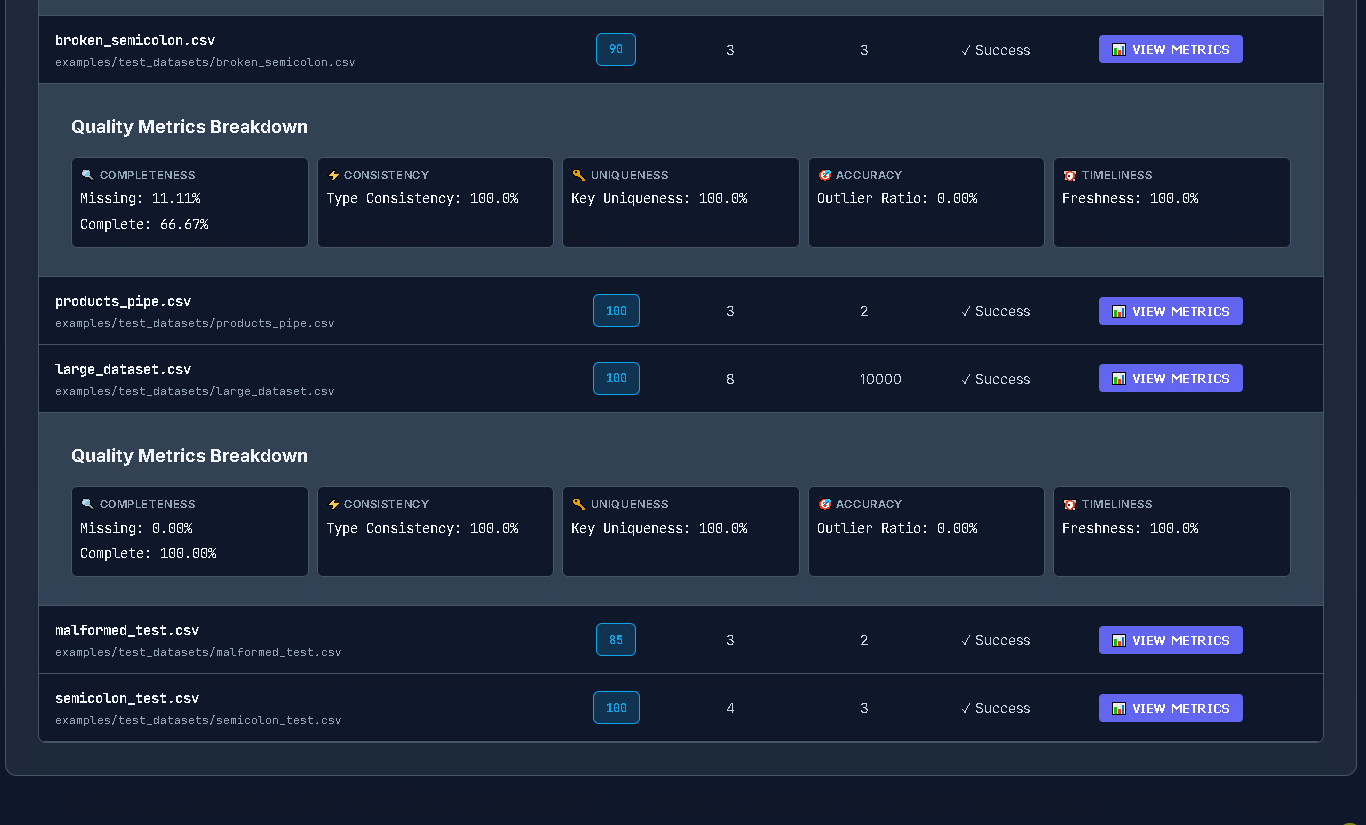
#### Batch Processing
```bash
# Process entire directory with parallel execution
dataprof batch /data/folder --recursive --parallel
# Generate HTML batch dashboard
dataprof batch /data/folder --recursive --html batch_report.html
# JSON export for CI/CD automation
dataprof batch /data/folder --json batch_results.json --recursive
# JSON output to stdout
dataprof batch /data/folder --format json --recursive
# With custom filter and progress
dataprof batch /data/folder --filter "*.csv" --parallel --progress
```
#### Database Analysis
```bash
# PostgreSQL table profiling
dataprof database postgres://user:pass@host/db --table users
# Custom SQL query
dataprof database sqlite://data.db --query "SELECT * FROM users WHERE active=1"
```
#### Benchmarking
```bash
# Benchmark different engines on your data
dataprof benchmark data.csv
# Show engine information
dataprof benchmark --info
```
#### Advanced Options
```bash
# Streaming for large files
dataprof analyze large_dataset.csv --streaming --sample 10000
# JSON output for programmatic use
dataprof analyze data.csv --format json --output results.json
# Custom ISO threshold profile
dataprof analyze data.csv --threshold-profile strict
```
**Quick Reference**: All commands follow the pattern `dataprof <command> [args]`. Use `dataprof help` or `dataprof <command> --help` for detailed options.
### Python Bindings
```bash
pip install dataprof
```
```python
import dataprof
# Comprehensive quality analysis (ISO 8000/25012 compliant)
report = dataprof.analyze_csv_with_quality("data.csv")
print(f"Quality score: {report.quality_score():.1f}%")
# Access individual quality dimensions
metrics = report.data_quality_metrics
print(f"Completeness: {metrics.complete_records_ratio:.1f}%")
print(f"Consistency: {metrics.data_type_consistency:.1f}%")
print(f"Uniqueness: {metrics.key_uniqueness:.1f}%")
# Batch processing
result = dataprof.batch_analyze_directory("/data", recursive=True)
print(f"Processed {result.processed_files} files at {result.files_per_second:.1f} files/sec")
# Async database profiling (requires python-async feature)
import asyncio
async def profile_db():
result = await dataprof.profile_database_async(
"postgresql://user:pass@localhost/db",
"SELECT * FROM users LIMIT 1000",
batch_size=1000,
calculate_quality=True
)
print(f"Quality score: {result['quality'].overall_score:.1%}")
asyncio.run(profile_db())
```
> **Note**: Async database profiling requires building with `--features python-async,database,postgres` (or mysql/sqlite). See [Async Support](#async-support) below.
**[Full Python API Documentation →](docs/python/README.md)**
### Rust Library
```bash
cargo add dataprof
```
```rust
use dataprof::*;
// High-performance Arrow processing for large files (>100MB)
// Requires compilation with: cargo build --features arrow
#[cfg(feature = "arrow")]
let profiler = DataProfiler::columnar();
#[cfg(feature = "arrow")]
let report = profiler.analyze_csv_file("large_dataset.csv")?;
// Standard adaptive profiling (recommended for most use cases)
let profiler = DataProfiler::auto();
let report = profiler.analyze_file("dataset.csv")?;
```
## Development
Want to contribute or build from source? Here's what you need:
### Prerequisites
- Rust (latest stable via [rustup](https://rustup.rs/))
- Docker (for database testing)
### Quick Setup
```bash
git clone https://github.com/AndreaBozzo/dataprof.git
cd dataprof
cargo build --release # Build the project
docker-compose -f .devcontainer/docker-compose.yml up -d # Start test databases
```
### Feature Flags
dataprof uses optional features to keep compile times fast and binaries lean:
```bash
# Minimal build (CSV/JSON only, ~60s compile)
cargo build --release
# With Apache Arrow (columnar processing, ~90s compile)
cargo build --release --features arrow
# With Parquet support (requires arrow, ~95s compile)
cargo build --release --features parquet
# With database connectors
cargo build --release --features postgres,mysql,sqlite
# With Python async support (for async database profiling)
maturin develop --features python-async,database,postgres
# All features (full functionality, ~130s compile)
cargo build --release --all-features
```
**When to use Arrow?**
- ✅ Files > 100MB with many columns (>20)
- ✅ Columnar data with uniform types
- ✅ Need maximum throughput (up to 13x faster)
- ❌ Small files (<10MB) - standard engine is faster
- ❌ Mixed/messy data - streaming engine handles better
**When to use Parquet?**
- ✅ Analytics workloads with columnar data
- ✅ Data lake architectures
- ✅ Integration with Spark, Pandas, PyArrow
- ✅ Efficient storage and compression
- ✅ Type-safe schema preservation
### Async Support
DataProf supports asynchronous operations for non-blocking database profiling, both in Rust and Python.
#### Rust Async (Database Features)
Database connectors are fully async and use `tokio` runtime:
```rust
use dataprof::database::{DatabaseConfig, profile_database};
#[tokio::main]
async fn main() -> Result<()> {
let config = DatabaseConfig {
connection_string: "postgresql://localhost/mydb".to_string(),
batch_size: 10000,
..Default::default()
};
let report = profile_database(config, "SELECT * FROM users").await?;
println!("Profiled {} rows", report.total_rows);
Ok(())
}
```
**Available async features:**
- ✅ Non-blocking database queries
- ✅ Concurrent query execution
- ✅ Streaming for large result sets
- ✅ Connection pooling with SQLx
- ✅ Retry logic with exponential backoff
#### Python Async (python-async Feature)
Enable async Python bindings for database profiling:
```bash
# Build with async support
maturin develop --features python-async,database,postgres
```
```python
import asyncio
import dataprof
async def main():
# Test connection
connected = await dataprof.test_connection_async(
"postgresql://user:pass@localhost/db"
)
# Get table schema
columns = await dataprof.get_table_schema_async(
"postgresql://user:pass@localhost/db",
"users"
)
# Count rows
count = await dataprof.count_table_rows_async(
"postgresql://user:pass@localhost/db",
"users"
)
# Profile database query
result = await dataprof.profile_database_async(
"postgresql://user:pass@localhost/db",
"SELECT * FROM users LIMIT 1000",
batch_size=1000,
calculate_quality=True
)
print(f"Quality score: {result['quality'].overall_score:.1%}")
asyncio.run(main())
```
**Benefits:**
- ✅ Non-blocking I/O for better performance
- ✅ Concurrent database profiling
- ✅ Integration with async Python frameworks (FastAPI, aiohttp, etc.)
- ✅ Efficient resource usage
**See also:** [examples/async_database_example.py](examples/async_database_example.py) for complete examples.
### Common Development Tasks
```bash
cargo test # Run all tests
cargo bench # Performance benchmarks
cargo fmt # Format code
cargo clippy # Code quality checks
```
## Documentation
### Privacy & Transparency
- [What DataProf Does](docs/WHAT_DATAPROF_DOES.md) - **Complete transparency guide with source code verification**
### User Guides
- [Python API Reference](docs/python/API_REFERENCE.md) - Full Python API documentation
- [Python Integrations](docs/python/INTEGRATIONS.md) - Pandas, scikit-learn, Jupyter, Airflow, dbt
- [Database Connectors](docs/guides/database-connectors.md) - Production database connectivity
- [Apache Arrow Integration](docs/guides/apache-arrow-integration.md) - Columnar processing guide
- [CLI Usage Guide](docs/guides/CLI_USAGE_GUIDE.md) - Complete CLI reference
### Developer Guides
- [Development Guide](docs/DEVELOPMENT.md) - Complete setup and contribution guide
- [Performance Guide](docs/guides/performance-guide.md) - Optimization and benchmarking
- [Performance Benchmarks](docs/project/benchmarking.md) - Benchmark results and methodology
## License
Licensed under the MIT License. See [LICENSE](LICENSE) for details.