# DataProfiler 📊
[](https://github.com/AndreaBozzo/dataprof/actions)
[](LICENSE)
[](https://www.rust-lang.org)
[](https://crates.io/crates/dataprof)
[](https://pypi.org/project/dataprof/)
**High-performance data quality library for production pipelines**
🏗️ **Library-first design** for easy integration • ⚡ **10x faster** than pandas • 🌊 **Handles datasets larger than RAM** • 🔍 **Robust quality checking** for dirty data
## 🚀 Quick Start
### As a Rust Library
```bash
cargo add dataprof
```
```rust
use dataprof::*;
// Simple analysis
let profiles = analyze_csv("data.csv")?;
// Quality checking with streaming for large files
let report = analyze_csv_with_quality("large_dataset.csv")?;
if report.quality_score()? < 80.0 {
println!("⚠️ Data quality issues detected!");
for issue in report.issues {
println!("- {}: {}", issue.severity, issue.message);
}
}
// Advanced configuration
let profiler = DataProfiler::builder()
.streaming(true)
.quality_config(QualityConfig::strict())
.sampling_strategy(SamplingStrategy::reservoir(10000))
.build()?;
let report = profiler.analyze_file("dirty_data.csv")?;
```
### Integration Examples
<details>
<summary><b>🔧 Airflow Integration</b></summary>
```python
# Quality gate in Airflow DAG
from dataprof import quick_quality_check
def data_quality_check(**context):
file_path = context['task_instance'].xcom_pull(task_ids='extract_data')
quality_score = quick_quality_check(file_path)
if quality_score < 80.0:
raise AirflowException(f"Data quality too low: {quality_score}")
return quality_score
quality_task = PythonOperator(
task_id='check_data_quality',
python_callable=data_quality_check,
dag=dag
)
```
</details>
<details>
<summary><b>📊 dbt Integration</b></summary>
```rust
// Generate dbt tests from profiling results
use dataprof::integrations::dbt;
let report = analyze_csv_with_quality("models/customers.csv")?;
dbt::generate_tests(&report, "tests/customers.yml")?;
// Creates tests like:
// - dbt_utils.not_null_proportion(columns=['email'], at_least=0.95)
// - dbt_utils.accepted_range(column_name='age', min_value=0, max_value=120)
```
</details>
<details>
<summary><b>🐍 Python Bindings</b></summary>
```python
pip install dataprof
import dataprof
# Simple usage
profiles = dataprof.analyze_csv("data.csv")
quality_report = dataprof.analyze_with_quality("data.csv")
# Pandas integration
import pandas as pd
df = pd.read_csv("large_file.csv")
# DataProfiler handles larger datasets that crash pandas
profiles = dataprof.analyze_dataframe(df)
```
</details>
### CLI Usage
```bash
# Install binary from GitHub releases
# Basic analysis
./dataprof data.csv --quality
# Streaming for large files
./dataprof huge_dataset.csv --streaming --progress
# Generate HTML report
./dataprof data.csv --quality --html report.html
```
## 🎯 Real-World Use Cases
### Production Data Pipeline Quality Gates
```rust
// Block pipeline on poor data quality
let quality_score = quick_quality_check("incoming/batch_2024_01_15.csv")?;
if quality_score < 85.0 {
return Err("Data quality below production threshold");
}
```
### ML Model Input Validation
```rust
// Detect data drift in production
let baseline = analyze_csv("training_data.csv")?;
let current = analyze_csv("production_input.csv")?;
let drift_detected = detect_distribution_drift(&baseline, ¤t)?;
```
### ETL Process Monitoring
```rust
// Continuous monitoring of data warehouse loads
for file in glob("warehouse/daily/*.csv")? {
let report = analyze_csv_with_quality(&file)?;
send_quality_metrics(&report, "datadog://metrics")?;
}
```
## ⚡ Performance vs Alternatives
| **DataProfiler** | **2.1s** | **45MB** | **✅ Yes** |
| pandas.describe() | 8.4s | 380MB | ❌ No |
| Great Expectations | 12.1s | 290MB | ❌ No |
| deequ (Spark) | 15.3s | 1.2GB | ✅ Yes |
*Benchmarks on E5-2670v3, 16GB RAM, SSD*
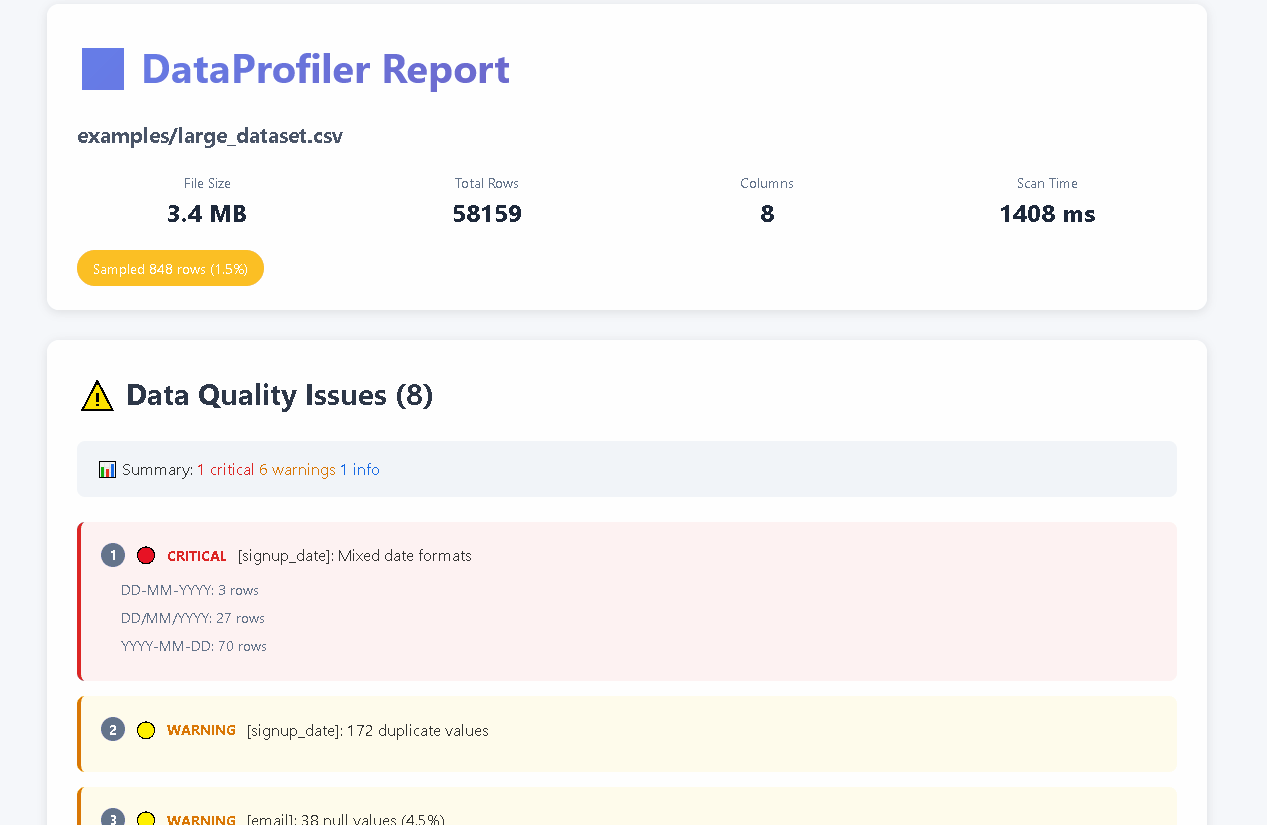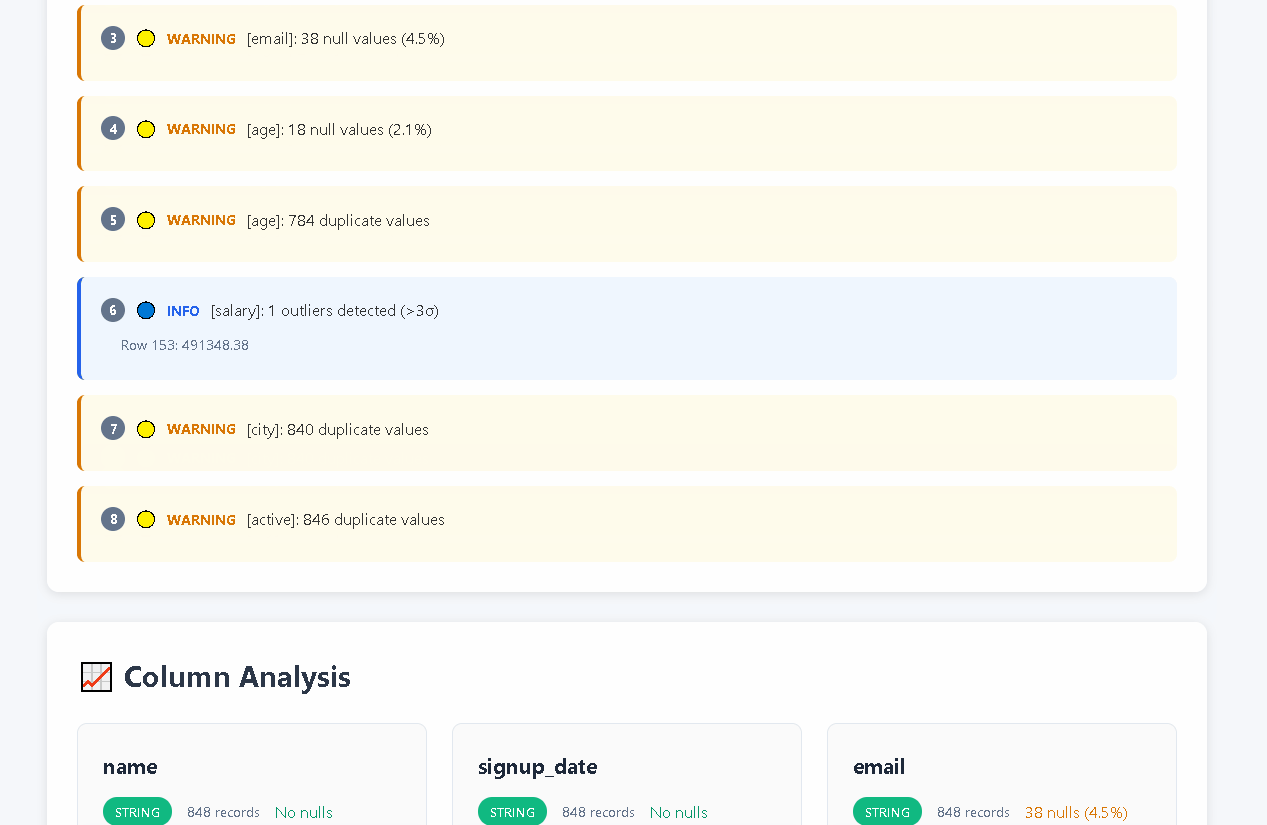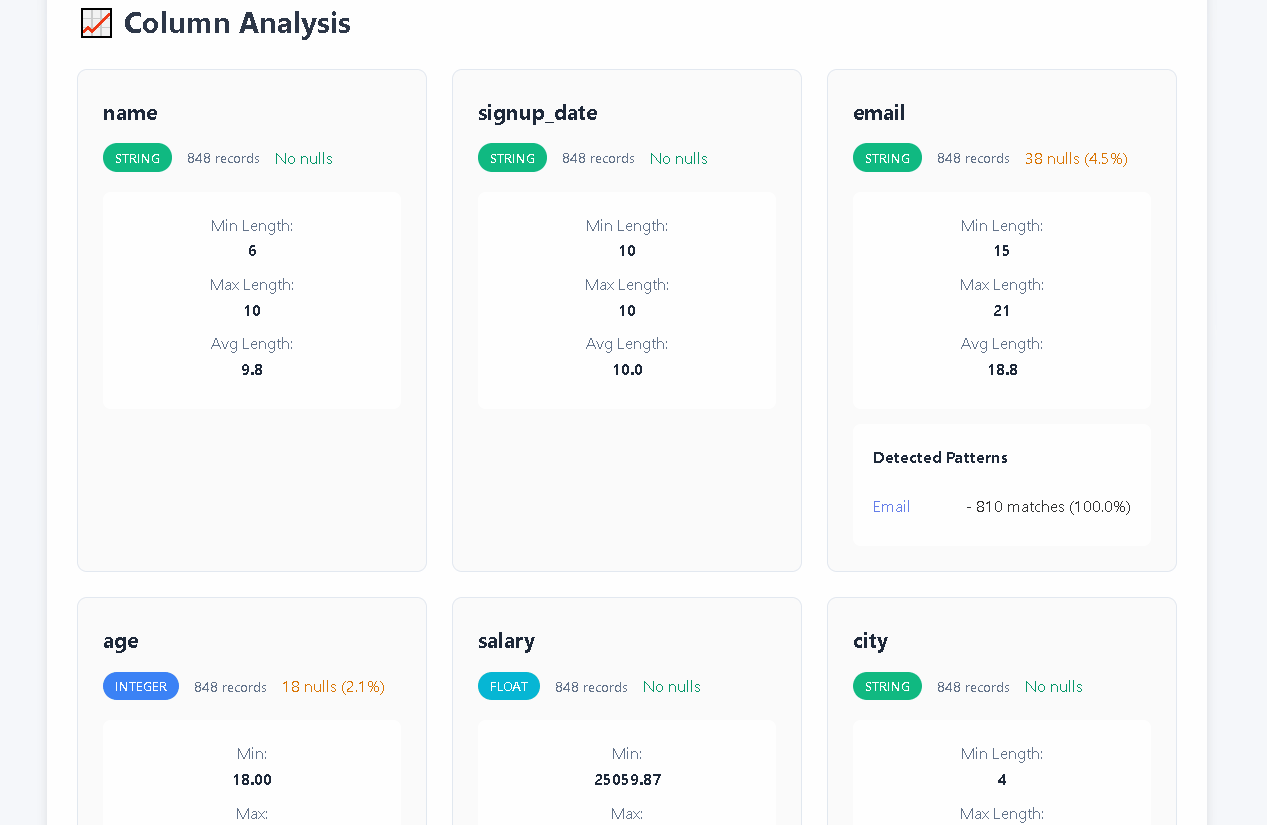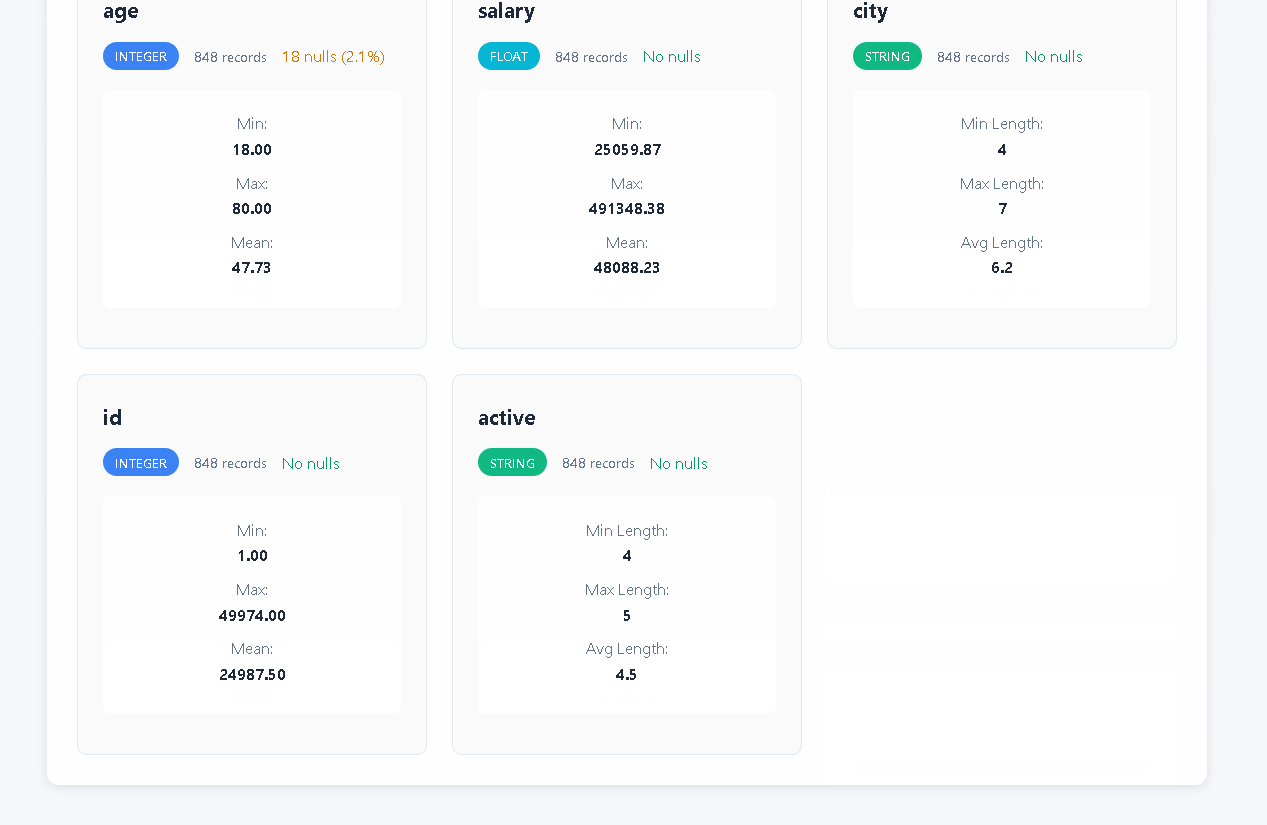
## 📊 Example Output
### Quality Issues Detection
```
⚠️ QUALITY ISSUES FOUND: (15)
1. 🔴 CRITICAL [email]: 2 null values (20.0%)
2. 🔴 CRITICAL [order_date]: Mixed date formats
- YYYY-MM-DD: 5 rows
- DD/MM/YYYY: 2 rows
- DD-MM-YYYY: 1 rows
3. 🟡 WARNING [phone]: Invalid format patterns detected
4. 🟡 WARNING [amount]: Outlier values (999999.99 vs mean 156.78)
📊 Summary: 2 critical, 13 warnings
Quality Score: 73.2/100 - BELOW THRESHOLD
```
### Quality Issues Detection
```
📊 DataProfiler - Standard Analysis
⚠️ QUALITY ISSUES FOUND: (15)
1. 🔴 CRITICAL [email]: 2 null values (20.0%)
2. 🔴 CRITICAL [order_date]: Mixed date formats
- DD/MM/YYYY: 2 rows
- YYYY-MM-DD: 5 rows
- YYYY/MM/DD: 1 rows
- DD-MM-YYYY: 1 rows
3. 🟡 WARNING [phone]: 1 null values (10.0%)
4. 🟡 WARNING [amount]: 1 duplicate values
📊 Summary: 2 critical 13 warnings
```
## 🏗️ Architecture & Features
### Why DataProfiler?
**Built for Production Data Pipelines:**
- ⚡ **10x faster** than pandas on large datasets
- 🌊 **Stream processing** - analyze 100GB+ files without loading into memory
- 🛡️ **Robust parsing** - handles malformed CSV, mixed data types, encoding issues
- 🔍 **Smart quality detection** - catches issues pandas misses
- 🏗️ **Library-first** - easy integration into existing workflows
### Core Capabilities
| **Large File Support** | ✅ Streaming | ❌ Memory bound | ❌ Memory bound |
| **Quality Detection** | ✅ Built-in | ⚠️ Manual | ✅ Rules-based |
| **Performance** | ✅ SIMD accelerated | ⚠️ Single-threaded | ❌ Spark overhead |
| **Integration** | ✅ Library API | ✅ Native Python | ⚠️ Configuration heavy |
| **Dirty Data** | ✅ Robust parsing | ❌ Fails on errors | ⚠️ Schema required |
### Technical Features
- **🚀 SIMD Acceleration**: Vectorized operations for 10x numeric performance
- **🌊 True Streaming**: Process files larger than available RAM
- **🧠 Smart Algorithms**: Vitter's reservoir sampling, statistical profiling
- **🛡️ Robust Parsing**: Handles malformed CSV, mixed encodings, variable columns
- **⚠️ Quality Detection**: Null patterns, duplicates, outliers, format inconsistencies
- **📊 Multiple Formats**: CSV, JSON, JSONL with unified API
- **🔧 Configurable**: Sampling strategies, quality thresholds, output formats
## 📋 All Options
```bash
Fast CSV data profiler with quality checking - v0.3.0 Streaming Edition
Usage: dataprof [OPTIONS] <FILE>
Arguments:
<FILE> CSV file to analyze
Options:
-q, --quality Enable quality checking (shows data issues)
--html <HTML> Generate HTML report (requires --quality)
--streaming Use streaming engine for large files (v0.3.0)
--progress Show progress during processing (requires --streaming)
--chunk-size <CHUNK_SIZE> Override chunk size for streaming (default: adaptive)
--sample <SAMPLE> Enable sampling for very large datasets
-h, --help Print help
```
## 🛠️ As a Library
Add to your `Cargo.toml`:
```toml
[dependencies]
dataprof = { git = "https://github.com/AndreaBozzo/dataprof.git" }
```
```rust
use dataprof::analyze_csv;
let profiles = analyze_csv("data.csv")?;
for profile in profiles {
println!("{}: {:?} ({}% nulls)",
profile.name,
profile.data_type,
profile.null_count as f32 / profile.total_count as f32 * 100.0);
}
```
## 🎯 Supported Formats
- **CSV**: Comma-separated values with auto-delimiter detection
- **JSON**: JSON arrays with object records
- **JSONL**: Line-delimited JSON (one object per line)
## ⚡ Performance
- **Small files** (<10MB): Analysis in milliseconds
- **Large files** (100MB+): Smart sampling maintains accuracy
- **SIMD optimized**: 10x faster numeric computations on modern CPUs
- **Memory bounded**: Process files larger than available RAM
- **Example**: 115MB file analyzed in 2.9s with 99.6% accuracy
## 🧪 Development
Requirements: Rust 1.70+
### Quick Setup
```bash
# Automated setup (installs pre-commit hooks, tools)
bash scripts/setup-dev.sh # Linux/macOS
# or
pwsh scripts/setup-dev.ps1 # Windows
# Manual setup
cargo build --release # Build optimized
cargo test # Run all tests
cargo fmt # Format code
cargo clippy # Lint code
```
### Development Tools
#### Using just (Recommended)
```bash
cargo install just # Install task runner
just # Show all tasks
just dev # Quick development cycle
just check # Full quality checks
just test-lib # Fast library tests
just example data.csv # Run example analysis
```
#### Using pre-commit (Quality Gates)
```bash
pip install pre-commit # Install pre-commit
pre-commit install # Install hooks
pre-commit run --all-files # Run all checks
```
#### Manual Commands
```bash
cargo build --release # Build optimized
cargo test --lib # Fast library tests
cargo test --test integration_tests # Integration tests
cargo test --test v03_comprehensive # Comprehensive tests
cargo fmt --all # Format code
cargo clippy --all-targets --all-features -- -D warnings # Lint
```
### Quality Assurance
The project uses automated quality checks:
- **Pre-commit hooks**: Format, lint, test on every commit
- **Continuous Integration**: 61/61 tests passing (100% success rate)
- **Code coverage**: All major functions tested
- **Performance benchmarks**: Verified 10x SIMD improvements
## 🤝 Contributing
See [CONTRIBUTING.md](CONTRIBUTING.md) for development guidelines.
## 📄 License
This project is licensed under the GNU General Public License v3.0 - see the [LICENSE](LICENSE) file for details.