
Cathar

Name: cathar is from Greek katharós (καθαρός), "pure, clean" — the same root as catharsis (κάθαρσις), a cleansing. That's the whole job: take a noisy recording and give back clean audio.

![]()


Cathar is a transparent, dependency-free audio restoration toolkit — in pure Rust. It works on a standalone audio file (WAV, MP3, FLAC, OGG, M4A) just as readily as the audio track inside a video (MP4, MKV); video is never required. Every stage is inspectable, tunable DSP — no opaque neural models, no black boxes, so a result you don't like is a knob you can turn rather than a model you have to re-roll. Cathar does three things and writes WAV, FLAC, or AIFF (chosen by the output extension):
- Restore — denoise (phase-coherent stereo), de-hum, de-wind, de-click, de-clip, de-reverb, spectral repair, de-plosive, de-rustle.
- Enhance — de-ess, breath removal, voice isolation, bandwidth extension.
- Level — loudness (LUFS) and peak normalisation for delivery.
No ffmpeg, no C/C++, no system libraries. Decoding is symphonia, the FFT is
realfft/rustfft, WAV writing is hound and FLAC is flacenc — all
pure Rust, so a single cargo build gives you a self-contained binary. Every
effect is also a plain function over &[f32], so the same pipeline drops
straight into a Rust program or a larger media-processing pipeline.
Quick start
Or from a checkout:
# A noisy interview straight off a camera → clean dialogue:
# Learn the room tone from a silent segment, then denoise with it:
# A restoration chain, one stage at a time:
# Generate a synthetic noisy tone to experiment with:
The toolkit
Every command reads any supported format and writes WAV (32-bit float), FLAC
(24-bit lossless), or AIFF (24-bit) — the container follows the --out
extension (.wav / .flac / .aif/.aiff, defaulting to WAV). They are
grouped here by what they fix; run them in any order, or chain them.
Reduce — pull noise out of the signal
| Command | What it does | Key flags |
|---|---|---|
denoise |
Broadband denoiser — spectral subtraction (default) or Wiener filter; --coherent keeps the stereo image stable |
--alpha 3.0, --beta 0.01, --noiseprint <f>, --wiener, --coherent |
noiseprint |
Learn a noise profile from a silence/room-tone clip → JSON | --out noise.np.json |
dehum |
Notch out mains hum (50/60 Hz) and its harmonics | --freq 60, --harmonics 5 |
dewind |
Cut low-frequency wind rumble with a 4th-order high-pass | --cutoff 80 |
dereverb |
Suppress room reverb by gating the spectral decay tail | --strength 2.0 |
voiceisolate |
Keep speech, gate everything else (energy VAD + spectral gate) | --noiseprint <f> |
deesser |
Tame harsh sibilance ("sss"); --bands >1 is multiband + adaptive |
--freq 4000, --threshold -24, --bands 1 |
deplosive |
Tame plosive "p"/"b" pops (low-frequency transient bursts) | --strength 4 |
derustle |
Suppress lavalier / clothing rustle (mid-band transient bursts) | --strength 4 |
breath |
Detect and high-pass the breaths before speech onsets | — |
Repair — reconstruct damaged samples
| Command | What it does | Key flags |
|---|---|---|
declick |
Detect impulse clicks against the local RMS and interpolate across them | --threshold 10.0 |
declip |
Find flat-topped clipped runs and rebuild the missing peaks | --threshold 0.95 |
repair |
Paint out isolated transient spectral artifacts (whistles, bursts, glitches) | --strength 4.0 |
Enhance & level
| Command | What it does | Key flags |
|---|---|---|
enhance |
Bandwidth extension — resample up and synthesise the missing highs | --rate 48000 |
normalize |
Loudness (LUFS, true EBU R128) or peak (dBFS) normalisation | --target -16, --peak, --true-peak -1 |
Utility
| Command | What it does | Key flags |
|---|---|---|
resample |
Resample to a different rate (anti-aliased, any ratio) | --rate 48000 |
wave |
Generate a synthetic sine + noise test tone | --freq 440, --duration 3, --noise 0.1, --sample-rate 44100 |
batch |
Denoise (and optionally de-hum / normalise) a whole directory | --indir, --outdir, --dehum <hz>, --normalize <lufs>, --exts |
--target for normalize is roughly: -23 broadcast (EBU R128), -16
podcast, -14 streaming.
How denoising works
Cathar decodes to interleaved f32 PCM, then most reduction stages run as an
STFT (short-time Fourier transform) → modify the spectrum → inverse STFT
loop. The denoiser uses a 2048-point FFT with a 512-sample hop (75 % overlap)
and a Hann window on both analysis and synthesis, reconstructed by overlap-add:
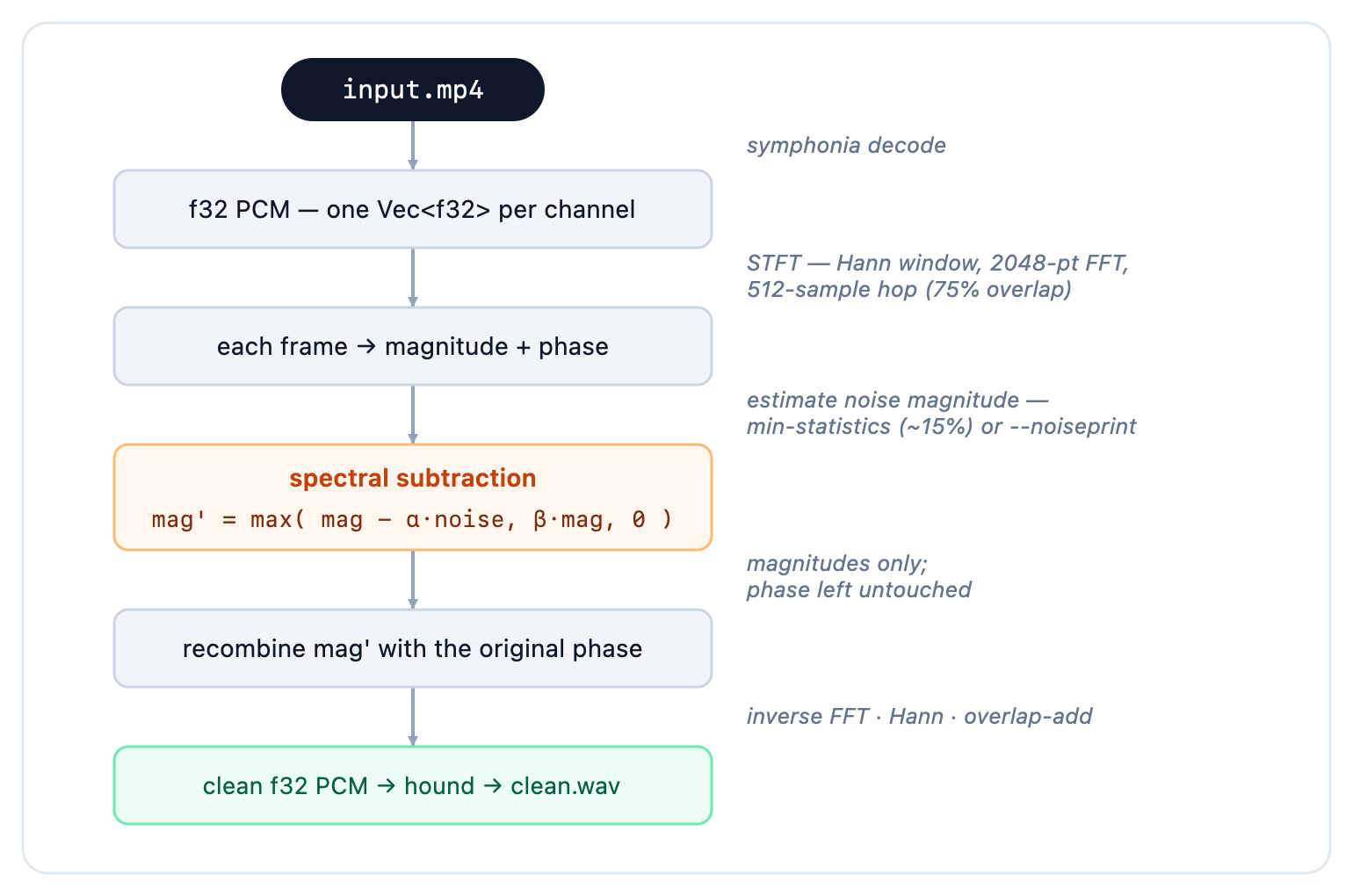
Two denoiser flavours share that frame loop:
- Spectral subtraction (default) — estimate the noise magnitude per bin and
subtract
α ×it, held above a spectral floorβ·magso you trade artifacts ("musical noise") against aggressiveness.αfrom 1→6 goes gentle→aggressive. - Wiener filter (
--wiener) — apply the statistically optimal per-bin gaingain = S / (S + N)from the estimated signal and noise power; smoother on stationary noise.
The noise spectrum comes either from minimum-statistics (the quietest ~15 %
of frames are taken as noise) or, for a cleaner result, from a noiseprint
learned off a dedicated silent segment.
Inside each tool
Every stage is classic, inspectable DSP — no black boxes.
| Tool | Technique |
|---|---|
denoise |
STFT 2048/512, Hann; spectral subtraction max(mag−α·N, β·mag) or Wiener S/(S+N). --coherent derives one gain mask from the mid (L+R) signal and applies it to every channel, so the stereo image stays put |
dewind |
4th-order Butterworth high-pass (two cascaded biquads, ~24 dB/oct) at --cutoff |
noiseprint |
Per-bin magnitude spectrum of a noise clip, serialised to JSON |
dehum |
Cascade of 2nd-order IIR notch biquads (Q = 30) at the base frequency and each harmonic up to Nyquist |
declick |
Sliding-window local RMS; samples exceeding threshold × RMS are clicks, replaced by cubic-Hermite interpolation |
declip |
Detect runs at/above threshold (shoulders extended ±4 samples), rebuild with cubic-Hermite interpolation |
repair |
STFT 2048/512; per bin, compare magnitude to its temporal median (±4 frames) and pull transient outliers back to the median, phase preserved — sustained content is untouched, overlap-add is window-normalised to unity |
dereverb |
Two-pass spectral-decay gating: track each bin's envelope (8 ms attack / 50 ms release), gate bins sitting near their reverb floor |
voiceisolate |
Energy VAD on 20 ms frames (gap-fill < 120 ms, drop segments < 50 ms) + spectral gating of non-speech (tighter with a noiseprint) |
deesser |
STFT 2048/256; single-band compresses the HF region when its power ratio exceeds the threshold. --bands >1 splits the sibilant region into sub-bands, each compressed when it rises threshold dB above its own EMA-tracked running level (multiband + adaptive) |
deplosive / derustle |
STFT; per frame measure energy in a band (plosive < 250 Hz, rustle 1.5–6 kHz); frames whose band energy spikes above the temporal median are scaled back toward it, phase preserved, sustained content untouched |
breath |
VAD-flag the frames just before a speech onset (≤ 150 ms) and high-pass them at 200 Hz, mixed 40 / 60 dry/wet |
resample |
Kaiser-windowed sinc (16 lobes, β = 9), arbitrary ratio; cutoff tracks the lower Nyquist so downsampling is anti-aliased and upsampling adds no imaging |
enhance |
Shared resampler to the target rate, then spectral band replication (4096 FFT) folds the existing top band into the empty highs with a tiled rolloff |
normalize |
Peak: scale so the loudest sample hits the dBFS target. Loudness: ITU-R BS.1770-4 / EBU R128 integrated LUFS (K-weighting, gated) measured jointly across channels, applied as one broadband gain and held back to the --true-peak dBTP ceiling (4× oversampled) so it never clips |
Library usage
The cathar crate is the same engine the CLI drives.
use ;
let audio = from_file?; // symphonia decode → f32
let sr = audio.sample_rate;
// Denoise and de-hum per channel via `map_channels`, then normalise to
// -16 LUFS (EBU R128) with a -1 dBTP true-peak ceiling. Loudness is measured
// across all channels jointly, so normalisation is a whole-signal method.
let clean = default
.denoise?
.map_channels
.normalize_r128;
clean.to_file?; // 32-bit float WAV via hound
Learn a noise print once and reuse it for a tighter subtraction:
use ;
let print = learn_noise_print?;
let audio = from_file?;
let clean = with_noise_print
.denoise?;
clean.to_file?;
The public surface is small and direct:
AudioData { sample_rate, channels: Vec<Vec<f32>> }—from_file,to_file,map_channels(|&[f32]| -> Vec<f32>)for per-channel effects,normalize_r128(target_lufs, true_peak_ceiling_db)for whole-signal loudness, andresample(target_rate)for the main-path resampler.Denoisertrait +SpectralDenoiser(configurablefft_size,hop_size,alpha,beta,noise_frame_ratio, optionalnoise_print);denoiseanddenoise_coherent(phase-coherent stereo).NoisePrint+learn_noise_print+wiener_denoise.- Free functions:
dehum,dewind,declick,declip,spectral_repair,deplosive,derustle,dereverb,voice_isolate,deesser,deess_multiband,breath_remove,bandwidth_extend,resample,normalize_peak,integrated_loudness,true_peak_dbtp,generate_wave.
Formats & I/O
| Stage | Detail |
|---|---|
| Reads | MP4, M4A, MKV, MP3, FLAC, WAV, OGG — any container/codec symphonia decodes (built with features = ["all"]) |
| Decodes to | 32-bit float PCM, one Vec<f32> per channel, at the file's native sample rate |
| Writes | 32-bit float WAV via hound — no inter-stage quantisation |
| Resampling | Only on the enhance path (windowed sinc); every other stage runs at the source rate |
| Channels | Preserved; effects run independently per channel |
Architecture
A deliberately small two-crate workspace — a library and the binary that drives it.
cathar/
├─ crates/
│ ├─ cathar/ # the engine: decode (symphonia) · DSP · encode (hound)
│ └─ cathar-cli/ # the `cathar` binary — clap subcommands over the engine
└─ docs/ # banner + assets
| Dependency | Role |
|---|---|
symphonia (all) |
Decode every supported container/codec to f32 PCM |
realfft / rustfft |
Forward/inverse real FFT behind every STFT stage |
hound |
Write 32-bit float WAV |
clap (derive) |
CLI parsing |
serde / serde_json |
NoisePrint serialisation (*.np.json) |
thiserror / anyhow |
Library error type / CLI error reporting |
candle-core, candle-nn |
(optional ml feature) scaffolding for a future learned denoiser |
Design
| Principle | What it means |
|---|---|
| Pure Rust | No ffmpeg, no C/C++ FFI, no pkg-config — one cargo build produces a self-contained binary |
| Lossless float pipeline | Decode → f32 → process → 32-bit float WAV; nothing is quantised between stages |
| Composable | Every effect is a plain fn(&[f32], …) -> Vec<f32>; chain them in any order, in the CLI or as a library |
| Inspectable DSP | Classic, documented algorithms (STFT subtraction, Wiener, IIR notches, cubic interpolation) — not opaque models |
| Deterministic | Single-threaded and frame-synchronous: the same input always yields the same output |
Pipeline integration
Because the whole toolbox is a library of &[f32] functions plus a single
static binary with no system dependencies, cathar slots cleanly into a larger
media pipeline: call it in-process through the cathar crate, or shell out to
cathar <stage> … between other steps. Inputs are read straight from the
container files, so it can sit immediately after ingest and before encoding.
Roadmap
Cathar is 0.4.x, restoration-first, and growing — before 1.0 — into a
general-purpose, pure-Rust audio swiss-army knife (a SoX-class tool with no
ffmpeg and no C/C++ FFI). See ROADMAP.md for the full plan and
SoX-parity checklist. The 0.2–0.4 foundations are complete:
- True EBU R128 loudness (
normalize) — K-weighted gated LUFS with a--true-peakdBTP ceiling. - Main-path resampling — the
resamplecommand +AudioData::resample, a shared anti-aliased Kaiser-windowed sinc any stage can call. - Encode beyond WAV — 24-bit lossless FLAC and 24-bit AIFF on the pure-Rust default path, selected by the output extension.
Next up is restoration depth (Phase 1 0.5) and the swiss-army expansion
(Phase 2) — see ROADMAP.md.
The optional ml feature wires in candle
for a learned denoiser (0.6); the neural model itself is not implemented yet.
Development
just check-all runs fmt-check, clippy (-D warnings), tests, and docs — the
same gate CI enforces on Linux and macOS.
| Task | Command |
|---|---|
| Build | just build / just build-release |
| Format | just fmt (just fmt-check to verify) |
| Lint | just lint |
| Test | just test |
| Docs | just docs |
| Audit | just deny (needs cargo install cargo-deny) |
| Run | just run -- <args> |
License
Licensed under either of Apache License, Version 2.0 or MIT license at your option.