Expand description
§Betlang

![]()
CPU source-language detection for code with a tiny 50kb model.
[dependencies]
betlang = "0.1.0"let detection = betlang::detect("fn main() { println!(\"hi\"); }");
assert_eq!(detection.language(), Some(betlang::Language::Rust));Use betlang::detect(source) for UTF-8 source strings or byte slices. It
returns a Detection; call Detection::language() to read the top language.
Call Detection::top_languages() when you need ranked probabilities.
§Supported Languages
Slugs parse through the standard FromStr implementation:
assert_eq!("rust".parse::<betlang::Language>(), Ok(betlang::Language::Rust));asm, batch, c, clojure, cmake, cobol, cpp, cs, css, dart,
dockerfile, elixir, erlang, gemfile, gemspec, go, gradle,
groovy, haskell, html, ini, java, javascript, json, julia,
kotlin, lisp, lua, markdown, objectivec, ocaml, perl, php,
powershell, python, r, ruby, rust, scala, shell, sql, swift,
toml, typescript, vba, verilog, xml, yaml.
These are the model’s 48 output labels. Runtime detections expose them one-to-one with no label aggregation.
The confusion matrix uses the same labels:
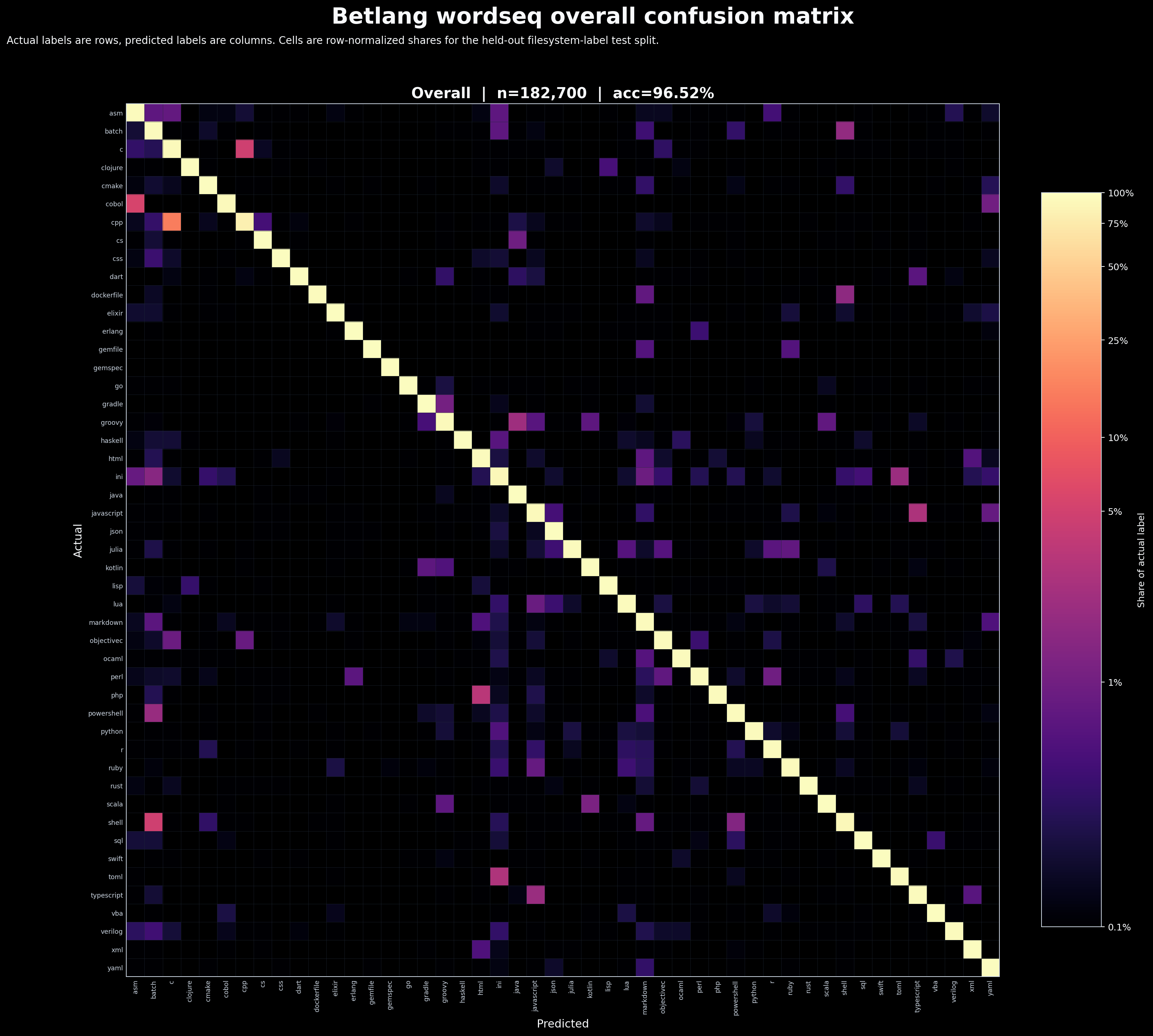
§Model
The embedded model is assets/magika/source-student-q4.bin, a 47,840-byte
weights-only MSQ1 payload with SHA-256:
59ef24167bddd1364eb9c1650add8a67e1a542b5155fac67f5e1cda07df0c0f0Architecture: wordseq-b1024-k3-m2048-tiny-3conv-hidden, tokenizer version 3.
On the manifest-aligned held-out filesystem-label test split it reaches
test_fs_accuracy=0.965238 with macro_recall=0.965411.
See MODEL_CARD.md for the training and evaluation summary.
§Performance
Betlang uses a fixed 4096-byte Magika window and pads runtime inference to the
same 2048-token shape used by evaluation. The model is loaded once per process
and then reused through a OnceLock.
Native CPU inference dispatches through fearless_simd. Benchmark entry points
are available through cargo bench. Current baseline numbers are tracked in
BENCHMARKS.md.
§License And Attribution
Betlang is licensed under MIT. The embedded student model was trained from outputs of Google’s Magika teacher model; Magika is published by Google under Apache-2.0. Keep this attribution with redistributed model artifacts.
§Confusion By File Size
The shipped wordseq model is evaluated below on the held-out bigorig test
split. Each panel is a row-normalized confusion matrix for one file-size
bucket: actual labels are rows, predicted labels are columns, and the diagonal
is correct classification.
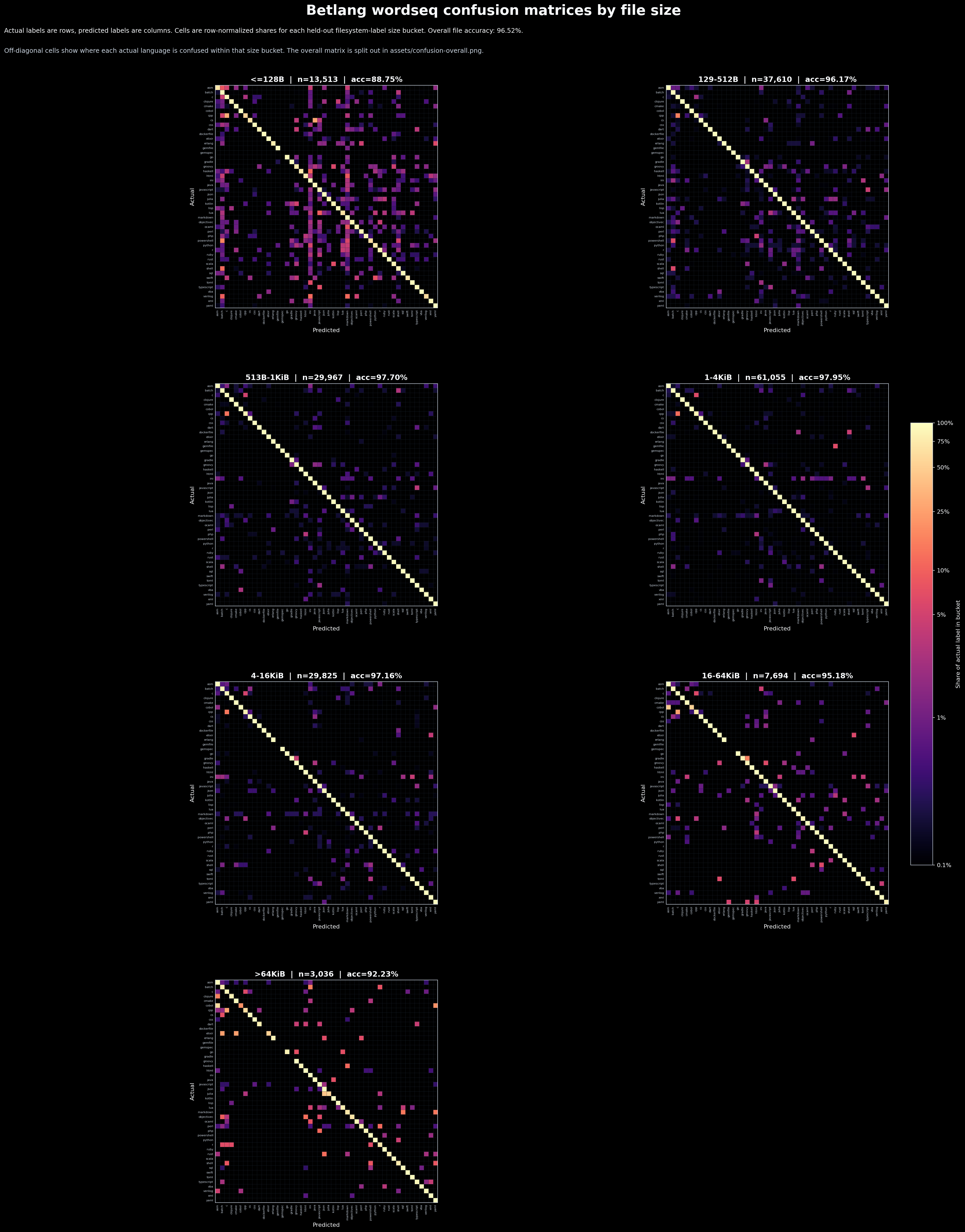
Structs§
- Detection
- Source-language detection result.
- Parse
Language Error - Error returned when parsing a
Languagefrom an unknown slug.
Enums§
- Language
- Source language predicted by the embedded Magika student model.
Functions§
- detect
- Detect the source language for bytes-like input.