Crate orx_concurrent_vec
source ·Expand description
§orx-concurrent-vec

![]()
An efficient, convenient and lightweight grow-only read & write concurrent data structure allowing high performance concurrent collection.
- convenient:
ConcurrentVeccan safely be shared among threads simply as a shared reference. It is aPinnedConcurrentColwith a special concurrent state implementation. UnderlyingPinnedVecand concurrent bag can be converted back and forth to each other. - efficient:
ConcurrentVecis a lock free structure making use of a few atomic primitives, this leads to high performance concurrent growth. You may see the details in benchmarks and further performance notes.
Note that ConcurrentVec is a read & write collection with the cost to store values wrapped with an optional and initializing memory on allocation. See ConcurrentBag for a write only and a more performant variant. Having almost identical api, switching between ConcurrentVec and ConcurrentBag is straightforward.
§Examples
The main feature of ConcurrentVec compared to concurrent bag is to enable safe reading while providing efficient growth. It is convenient to share the concurrent vector among threads. std::sync::Arc can be used; however, it is not required as demonstrated below.
use orx_concurrent_vec::*;
use orx_concurrent_bag::*;
use std::time::Duration;
#[derive(Default, Debug)]
struct Metric {
sum: i32,
count: i32,
}
impl Metric {
fn aggregate(self, value: &i32) -> Self {
Self {
sum: self.sum + value,
count: self.count + 1,
}
}
}
// record measurements in random intervals (read & write -> ConcurrentVec)
let measurements = ConcurrentVec::new();
let rf_measurements = &measurements; // just &self to share among threads
// collect metrics every 50 milliseconds (only write -> ConcurrentBag)
let metrics = ConcurrentBag::new();
let rf_metrics = &metrics; // just &self to share among threads
std::thread::scope(|s| {
// thread to store measurements as they arrive
s.spawn(move || {
for i in 0..100 {
std::thread::sleep(Duration::from_millis(i % 5));
// collect measurements and push to measurements vec
// simply by calling `push`
rf_measurements.push(i as i32);
}
});
// thread to collect metrics every 50 milliseconds
s.spawn(move || {
for _ in 0..10 {
// safely read from measurements vec to compute the metric
let metric = rf_measurements
.iter()
.fold(Metric::default(), |x, value| x.aggregate(value));
// push result to metrics bag
rf_metrics.push(metric);
std::thread::sleep(Duration::from_millis(50));
}
});
// thread to print out the values to the stdout every 100 milliseconds
s.spawn(move || {
let mut idx = 0;
loop {
let current_len = rf_measurements.len_exact();
let begin = idx;
for i in begin..current_len {
// safely read from measurements vec
if let Some(value) = rf_measurements.get(i) {
println!("[{}] = {:?}", i, value);
idx += 1;
} else {
idx = i;
break;
}
}
if current_len == 100 {
break;
}
std::thread::sleep(Duration::from_millis(100));
}
});
});
assert_eq!(measurements.len(), 100);
assert_eq!(metrics.len(), 10);§Construction
ConcurrentVec can be constructed by wrapping any pinned vector; i.e., ConcurrentVec<T> implements From<P: PinnedVec<Option<T>>>.
Likewise, a concurrent vector can be unwrapped to get the underlying pinned vector with into_inner method.
Further, there exist with_ methods to directly construct the concurrent bag with common pinned vector implementations.
use orx_concurrent_vec::*;
// default pinned vector -> SplitVec<Option<T>, Doubling>
let con_vec: ConcurrentVec<char> = ConcurrentVec::new();
let con_vec: ConcurrentVec<char> = Default::default();
let con_vec: ConcurrentVec<char> = ConcurrentVec::with_doubling_growth();
let con_vec: ConcurrentVec<char, SplitVec<Option<char>, Doubling>> = ConcurrentVec::with_doubling_growth();
let con_vec: ConcurrentVec<char> = SplitVec::new().into();
let con_vec: ConcurrentVec<char, SplitVec<Option<char>, Doubling>> = SplitVec::new().into();
// SplitVec with [Linear](https://docs.rs/orx-split-vec/latest/orx_split_vec/struct.Linear.html) growth
// each fragment will have capacity 2^10 = 1024
// and the split vector can grow up to 32 fragments
let con_vec: ConcurrentVec<char, SplitVec<Option<char>, Linear>> = ConcurrentVec::with_linear_growth(10, 32);
let con_vec: ConcurrentVec<char, SplitVec<Option<char>, Linear>> = SplitVec::with_linear_growth_and_fragments_capacity(10, 32).into();
// [FixedVec](https://docs.rs/orx-fixed-vec/latest/orx_fixed_vec/) with fixed capacity.
// Fixed vector cannot grow; hence, pushing the 1025-th element to this concurrent vector will cause a panic!
let con_vec: ConcurrentVec<char, FixedVec<Option<char>>> = ConcurrentVec::with_fixed_capacity(1024);
let con_vec: ConcurrentVec<char, FixedVec<Option<char>>> = FixedVec::new(1024).into();Of course, the pinned vector to be wrapped does not need to be empty.
use orx_concurrent_vec::*;
let split_vec: SplitVec<Option<i32>> = (0..1024).map(Some).collect();
let con_vec: ConcurrentVec<_> = split_vec.into();§Concurrent State and Properties
The concurrent state is modeled simply by an atomic length. Combination of this state and PinnedConcurrentCol leads to the following properties:
- Writing to a position of the collection does not block other writes, multiple writes can happen concurrently.
- Each position is written exactly once.
- ⟹ no write & write race condition exists.
- Only one growth can happen at a given time.
- Underlying pinned vector is always valid and can be taken out any time by
into_inner(self). - Reading a position while its being written will yield
Noneand will be omitted.
§Benchmarks
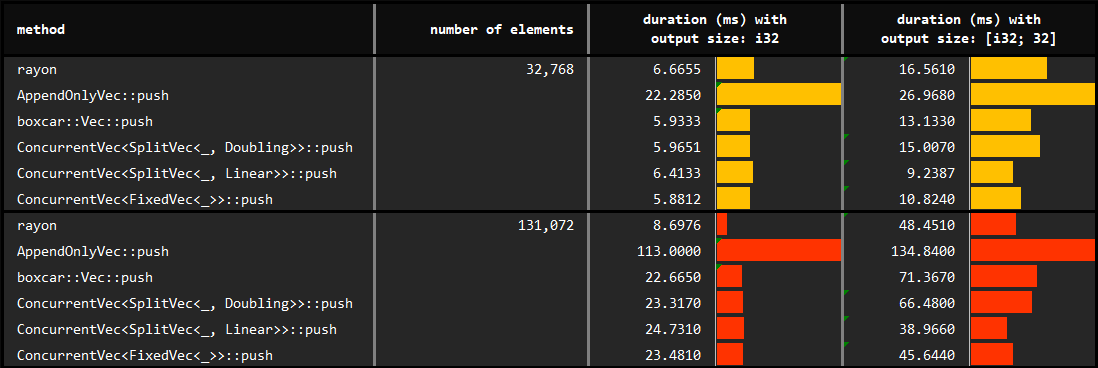
§Performance with push
You may find the details of the benchmarks at benches/collect_with_push.rs.
In the experiment, rayons parallel iterator and ConcurrentVecs push method are used to collect results from multiple threads.
// reserve and push one position at a time
for j in 0..num_items_per_thread {
bag_ref.push(i * 1000 + j);
}- We observe that rayon is significantly faster when the output is very small (
i32in this experiment). - As the output gets larger and copies become costlier (
[i32; 32]here),ConcurrentVec::pushstarts to perform equivalent to or faster than rayon. - Among the
ConcurrentVecvariants,LinearandFixedvariants perform faster than theDoublingvariant:- Here we observe the cost of memory initialization immediately on allocation. Since
Doublingvariant allocates more, initialization has a greater impact. ConcurrentBagdoes not perform this operation and it leads to a very high performance concurrent collection. Further, the impact of the underlying pinned vector type is insignificant. Therefore, it is a better choice when we only write results concurrently.- The main goal of
ConcurrentVec, on the other hand, is to enable safe reading while the vector concurrently grows, and it must be preferred in these situations over making unsafe calls. - Having almost identical api, switching between bag and vec is straightforward.
- Here we observe the cost of memory initialization immediately on allocation. Since
The issue leading to poor performance in the small data & little work situation can be avoided by using extend method in such cases. You may see its impact in the succeeding subsections and related reasons in the performance notes.
§Performance of extend
You may find the details of the benchmarks at benches/collect_with_extend.rs.
The only difference in this follow up experiment is that we use extend rather than push with ConcurrentVec. The expectation is that this approach will solve the performance degradation due to false sharing in the small data & little work situation.
// reserve num_items_per_thread positions at a time
// and then push as the iterator yields
let iter = (0..num_items_per_thread).map(|j| i * 100000 + j);
bag_ref.extend(iter);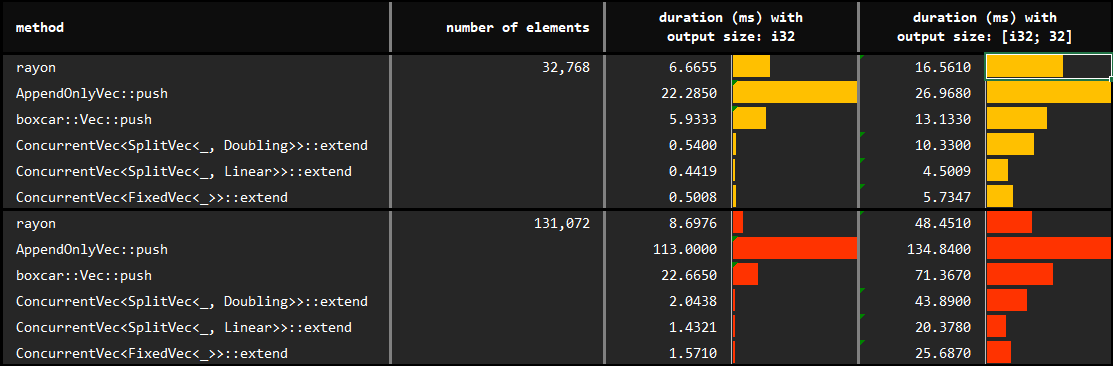
Note that we do not need to have perfect information on the number of items to be pushed per thread to get the benefits of extend, we can simply step_by. Extending by batch_size elements will already prevent the dramatic performance degradation provided that batch_size elements exceed a cache line.
// reserve batch_size positions at a time
// and then push as the iterator yields
for j in (0..num_items_per_thread).step_by(batch_size) {
let iter = (j..(j + batch_size)).map(|j| i * 100000 + j);
bag_ref.extend(iter);
}§Performance Notes
ConcurrentVec is an efficient read-and-write collection. However, it is important to avoid false sharing risk which might lead to a significant performance degradation. Details can be read here.
§License
This library is licensed under MIT license. See LICENSE for details.
Structs§
- An efficient, convenient and lightweight grow-only read & write concurrent data structure allowing high performance concurrent collection.
- Strategy which allows creates a fragment with double the capacity of the prior fragment every time the split vector needs to expand.
- A fixed vector,
FixedVec, is a vector with a strict predetermined capacity (seeSplitVecfor dynamic capacity version). - Strategy which allows the split vector to grow linearly.
- Equivalent to
Doublingstrategy except for the following: - A split vector; i.e., a vector of fragments, with the following features:
Traits§
- Trait for vector representations differing from
std::vec::Vecby the following: