Expand description
Criterion benchmark harness designed to compare different modes of distributing work in a many-processor system with multiple memory regions. This helps highlight the performance impact of cross-memory-region data transfers, cross-processor data transfers and multi-threaded logic.
This is part of the Folo project that provides mechanisms for high-performance hardware-aware programming in Rust.
§Execution model
The benchmark harness selects pairs of processors that will execute each iteration of a benchmark scenario, preparing and processing payloads. The iteration time is the maximum duration of any worker (whichever worker takes longest to process the payload it is given).
The criteria for processor pairs selection is determined by the specified WorkDistribution,
with the final selection randomized for each iteration if there are multiple equally valid candidate
processor pairs.
§Usage
For each benchmark scenario, define a type that implements the Payload trait. Executing a
benchmark scenario consists of the following major steps:
- For each processor pair, a payload pair is created.
- Each payload is moved to its assigned processor and prepared. This is where the payload data set is typically generated.
- Depending on the work distribution mode, the payloads may now be exchanged between the assigned processors, to ensure that we process “foreign” data on each processor.
- The payload is processed by each worker in the pair. This is the timed step.
The reference to “foreign” data here implies that if the two workers are in different memory regions, the data is likely to be present in a different memory region than used by the processor used to process the payload.
This is because physical memory pages of heap-allocated objects are allocated in the memory region of the processor that initializes the memory (in the “prepare” step), so despite the payload later being moved to a different worker’s thread, any heap-allocated data referenced by the payload remains where it is, which may be in physical memory modules that are not directly connected to the processor that will process the payload.
§Example
A simple scenario that merely copies memory from a foreign buffer to a local one
(benches/many_cpus_harness_demo.rs):
const COPY_BYTES_LEN: usize = 64 * 1024 * 1024;
/// Sample benchmark scenario that copies bytes between the two paired payloads.
///
/// The source buffers are allocated in the "prepare" step and become local to the "prepare" worker.
/// The destination buffers are allocated in the "process" step. The end result is that we copy
/// from remote memory (allocated in the "prepare" step) to local memory in the "process" step.
///
/// There is no deep meaning behind this scenario, just a sample benchmark that showcases comparing
/// different work distribution modes to identify performance differences from hardware-awareness.
#[derive(Debug, Default)]
struct CopyBytes {
from: Option<Vec<u8>>,
}
impl Payload for CopyBytes {
fn new_pair() -> (Self, Self) {
(Self::default(), Self::default())
}
fn prepare(&mut self) {
self.from = Some(vec![99; COPY_BYTES_LEN]);
}
fn process(&mut self) {
let from = self.from.as_ref().unwrap();
let mut to = Vec::with_capacity(COPY_BYTES_LEN);
// SAFETY: The pointers are valid, the length is correct, all is well.
unsafe {
ptr::copy_nonoverlapping(from.as_ptr(), to.as_mut_ptr(), COPY_BYTES_LEN);
}
// SAFETY: We just filled these bytes, it is all good.
unsafe {
to.set_len(COPY_BYTES_LEN);
}
// Read from the destination to prevent the compiler from optimizing the copy away.
_ = black_box(to[0]);
}
}This scenario is executed in a Criterion benchmark by calling execute_runs() and providing
the desired work distribution modes to use:
fn entrypoint(c: &mut Criterion) {
execute_runs::<CopyBytes, 1>(c, WorkDistribution::all());
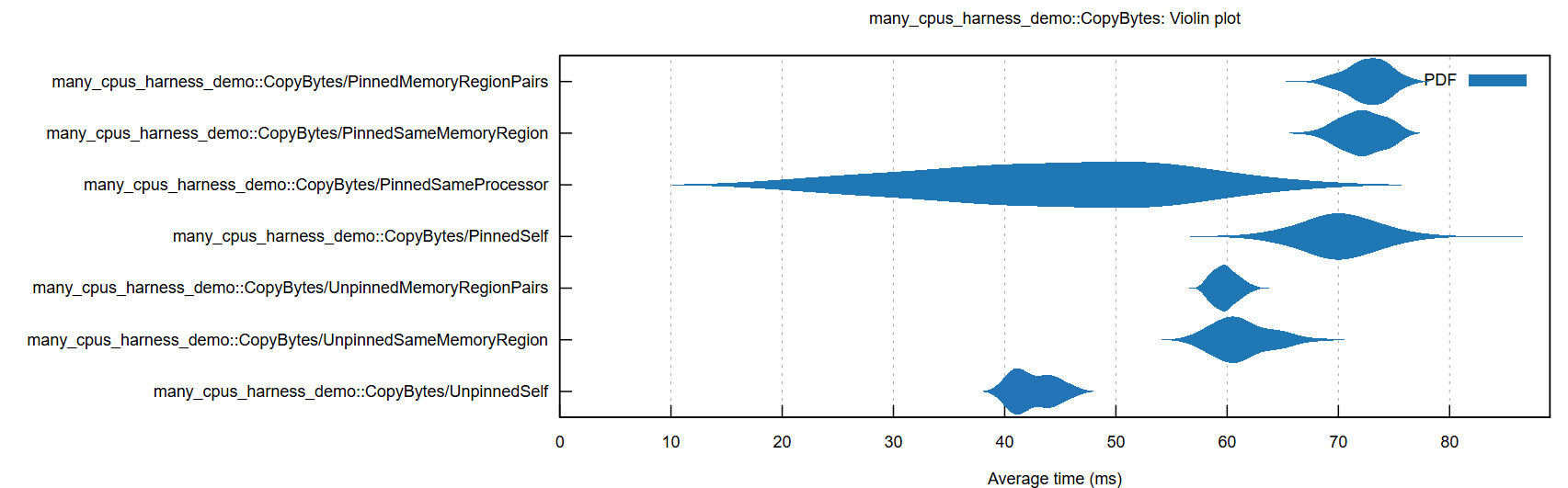
}Example output (in target/criterion/report after benchmarking):
§Step-by-step guides for common scenarios
The following sections provide detailed guidance for implementing the most important multi-threaded benchmarking scenarios using this crate.
§Scenario 1: Multiple threads performing the same action on shared data
This scenario is useful for measuring how memory locality affects performance when multiple threads perform identical operations on shared data structures. Examples include concurrent readers of a shared cache, multiple workers processing items from a shared queue using the same algorithm, or parallel searchers scanning the same dataset.
§Step-by-step implementation
- Define the payload struct with shared data wrapped in thread-safe containers:
use std::collections::HashMap;
use std::sync::{Arc, RwLock};
use many_cpus_benchmarking::Payload;
#[derive(Debug, Default)]
struct SharedDataSameAction {
// Shared data structure accessible by both workers
shared_map: Arc<RwLock<HashMap<u64, u64>>>,
// Flag to designate which worker initializes the data
is_initializer: bool,
}- Implement
new_pair()to create connected payload instances:
impl Payload for SharedDataSameAction {
fn new_pair() -> (Self, Self) {
let shared_map = Arc::new(RwLock::new(HashMap::new()));
let worker1 = Self {
shared_map: Arc::clone(&shared_map),
is_initializer: true,
};
let worker2 = Self {
shared_map,
is_initializer: false,
};
(worker1, worker2)
}
fn prepare(&mut self) {
// Only one worker initializes the shared data
if self.is_initializer {
let mut map = self.shared_map.write().unwrap();
for i in 0..1000 {
map.insert(i, i * 2);
}
}
}
fn process(&mut self) {
// Both workers perform the same operation
let map = self.shared_map.read().unwrap();
for key in 0..1000 {
std::hint::black_box(map.get(&key));
}
}
}- Choose appropriate work distribution modes. Since both workers perform the same action, payload exchange does not change the benchmark semantics, so you can exclude “self” modes:
use criterion::Criterion;
use many_cpus_benchmarking::{WorkDistribution, execute_runs};
fn benchmark_shared_reads(c: &mut Criterion) {
// Focus on distribution modes that use different processors
execute_runs::<SharedDataSameAction, 100>(
c,
WorkDistribution::all_with_unique_processors_without_self()
);
}§Key considerations for this scenario
- Use thread-safe containers like
Arc<RwLock<T>>or lock-free data structures - Designate one worker as the initializer to avoid race conditions during setup
- Both workers should perform identical operations in
process() - Consider using
WorkDistribution::all_with_unique_processors_without_self()since payload exchange does not affect the benchmark when workers do the same thing - Memory locality effects will be most visible when workers are in different memory regions
§Scenario 2: Multiple threads performing different actions (producer-consumer pattern)
This scenario measures performance when threads have complementary roles, such as producer-consumer pairs, sender-receiver communication, or writer-reader patterns. This is essential for understanding how memory locality affects inter-thread communication.
§Step-by-step implementation
- Define the payload struct with communication mechanisms and role identifiers:
use std::sync::mpsc;
use many_cpus_benchmarking::Payload;
#[derive(Debug)]
struct ProducerConsumerPattern {
// Communication channels
sender: mpsc::Sender<u64>,
receiver: mpsc::Receiver<u64>,
// Role identifier
is_producer: bool,
}- Implement
new_pair()to create complementary worker roles:
impl Payload for ProducerConsumerPattern {
fn new_pair() -> (Self, Self) {
let (tx1, rx1) = mpsc::channel();
let (tx2, rx2) = mpsc::channel();
let producer = Self {
sender: tx1,
receiver: rx2,
is_producer: true,
};
let consumer = Self {
sender: tx2,
receiver: rx1,
is_producer: false,
};
(producer, consumer)
}
fn prepare(&mut self) {
// Pre-populate channels to avoid deadlocks
for i in 0..1000 {
let _ = self.sender.send(i);
}
}
fn process(&mut self) {
if self.is_producer {
// Producer: mostly sends data
for i in 0..5000 {
let _ = self.sender.send(i);
if i % 10 == 0 {
if let Ok(response) = self.receiver.try_recv() {
std::hint::black_box(response);
}
}
}
} else {
// Consumer: mostly receives and processes data
for _ in 0..5000 {
// Use blocking recv() to ensure consistent work per iteration
if let Ok(data) = self.receiver.recv() {
let processed = data * 2;
std::hint::black_box(processed);
if data % 5 == 0 {
let _ = self.sender.send(processed);
}
}
}
}
}
}- Use all work distribution modes since different worker roles make payload exchange meaningful:
use criterion::Criterion;
use many_cpus_benchmarking::{WorkDistribution, execute_runs};
fn benchmark_producer_consumer(c: &mut Criterion) {
// All distribution modes are relevant for different worker roles
execute_runs::<ProducerConsumerPattern, 200>(
c,
WorkDistribution::all_with_unique_processors()
);
}§Key considerations for this scenario
- Design complementary roles that represent realistic workload patterns
- Use communication primitives appropriate for your use case (channels, shared memory, etc.)
- Pre-populate communication channels in
prepare()to avoid deadlocks - Include all work distribution modes since role differences make payload exchange meaningful
- Consider bidirectional communication to create realistic interaction patterns
- Be aware that some distribution modes like
PinnedSameProcessormay not be suitable for scenarios requiring real-time collaboration between workers
§Choosing the right work distribution modes
Different scenarios benefit from different work distribution mode selections:
- Same action scenarios: Use
WorkDistribution::all_with_unique_processors_without_self()to focus on memory locality effects without payload exchange overhead - Different action scenarios: Use
WorkDistribution::all_with_unique_processors()to include both memory locality and payload exchange effects - All scenarios: Use
WorkDistribution::all()to get the complete picture including same-processor execution modes
For complete working examples, see:
examples/shared_data_same_action.rs- Multiple readers of sharedHashMapexamples/shared_data_different_actions.rs- Producer-consumer channel communication
§Payload multiplier
It may sometimes be desirable to multiply the size of a benchmark scenario, e.g. if a scenario is very fast and completes too quickly for meaningful or comparable measurements due to the worker orchestration overhead.
Use the second generic parameter of execute_runs to apply a multiplier to the payload size. This
simply uses multiple payloads for each iteration (on the same worker), allowing the impact from the
benchmark harness overheads to be reduced, so the majority of the time is spent on payload
processing.
Enums§
- Work
Distribution - How work is distributed among processors during a benchmark run.
Traits§
- Payload
- One benchmark payload, to be processed by each worker involved in each benchmark.
Functions§
- execute_
runs - Executes a number of benchmark runs for a specific payload type, using the specified work distribution modes.