
libmdbx rust 封装
libmdbx 数据库的 rust 封装。
目录 :
[[toc]]
引子
在写『人民网络』的时候,感觉自己需要一个嵌入式数据库。
因为涉及到网络吞吐的记录,读写频繁,sqlite3 太高级性能堪忧。
所以用更底层的键值数据库更为合适(lmdb 比 sqlite 快 10 倍)。
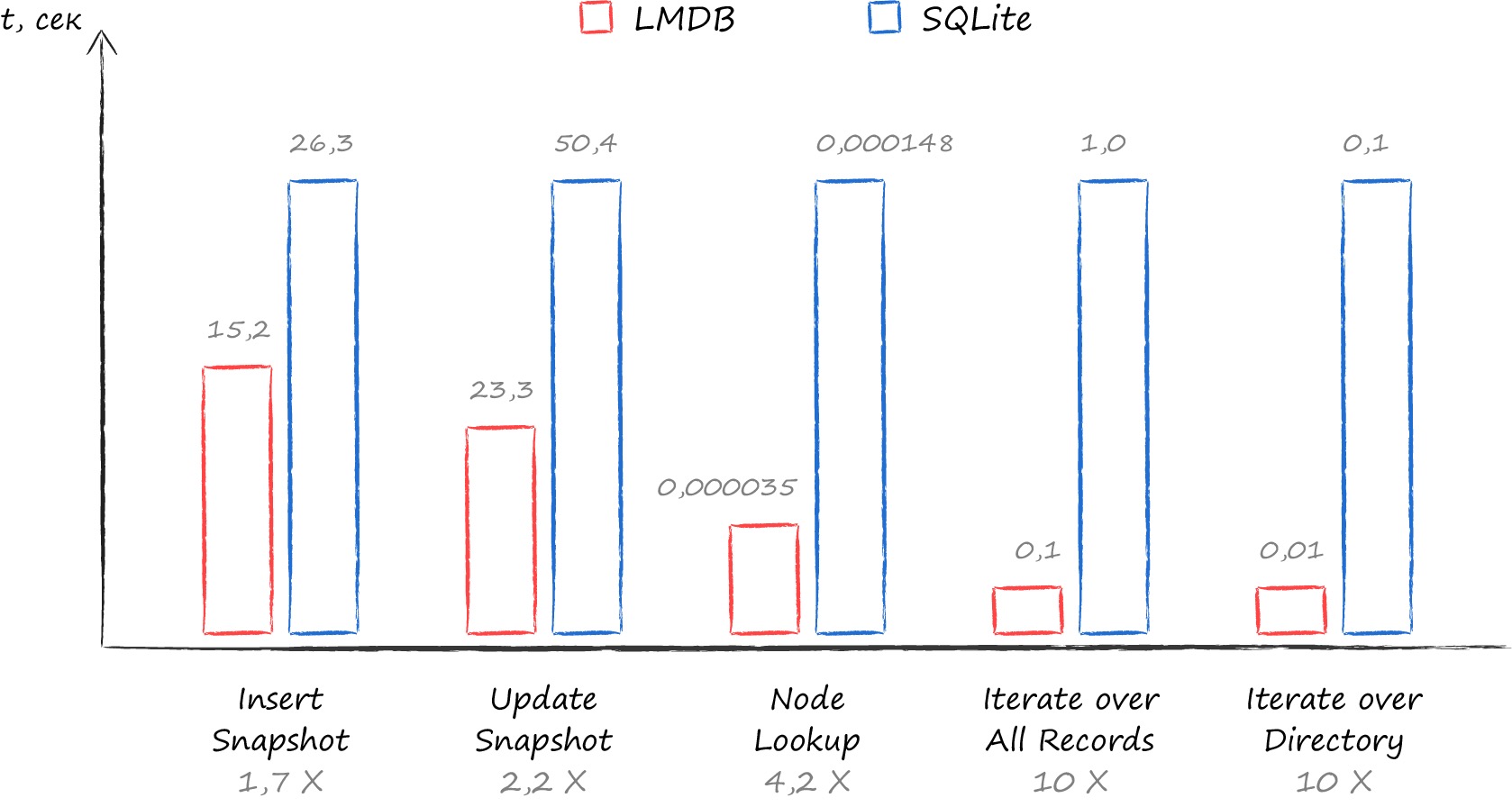
最终,我选择了 lmdb 的魔改版 —— mdbx 。
目前,现有的 mdbx 的 rust 封装 mdbx-rs(mdbx-sys)不支持 windows,于是我自己动手封装一个支持 windows 的版本。
我在易用性上做了大量工作。比如,可以一个模块中用 lazy_static 定义好所有数据库,然后用 use 引入,并且支持多线程访问。可以存储和读取自定义的数据类型。
同时,支持多线程,用起来会很方便。
libmdbx 是什么?
mdbx 是基于 lmdb 二次开发的数据库 ,作者是俄罗斯人 Леонид Юрьев (Leonid Yuriev)。
lmdb 是一个超级快的嵌入式键值数据库。
全文搜索引擎 MeiliSearch 就是基于 lmdb 开发的。
mdbx 在嵌入式性能测试基准 ioarena 中 lmdb 还要快 30% 。
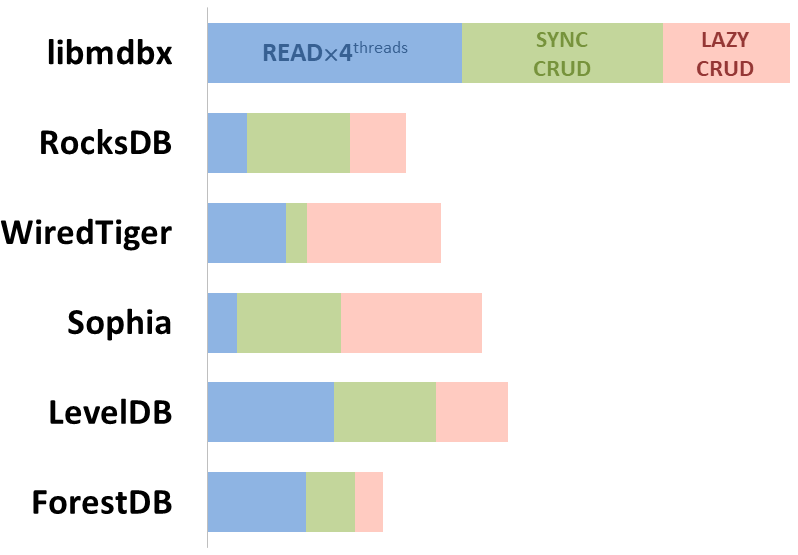
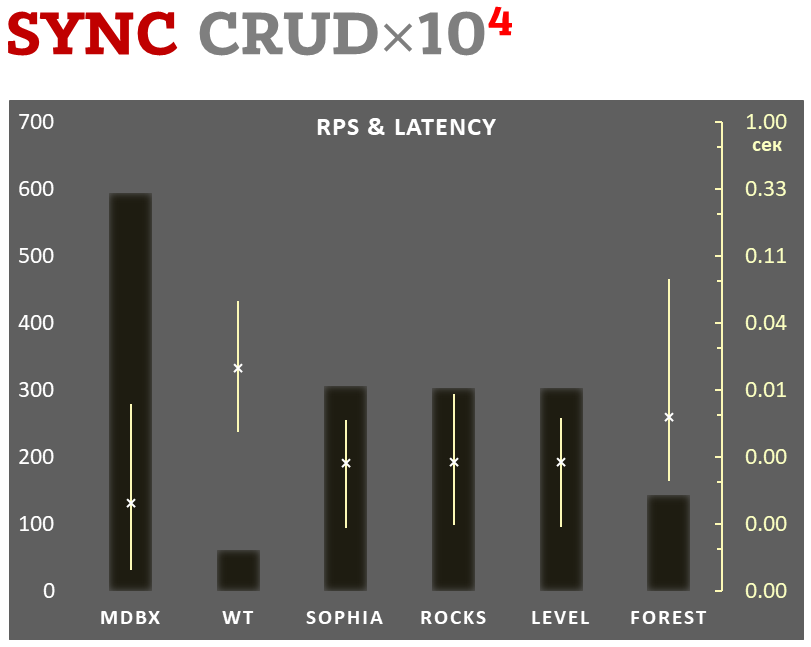
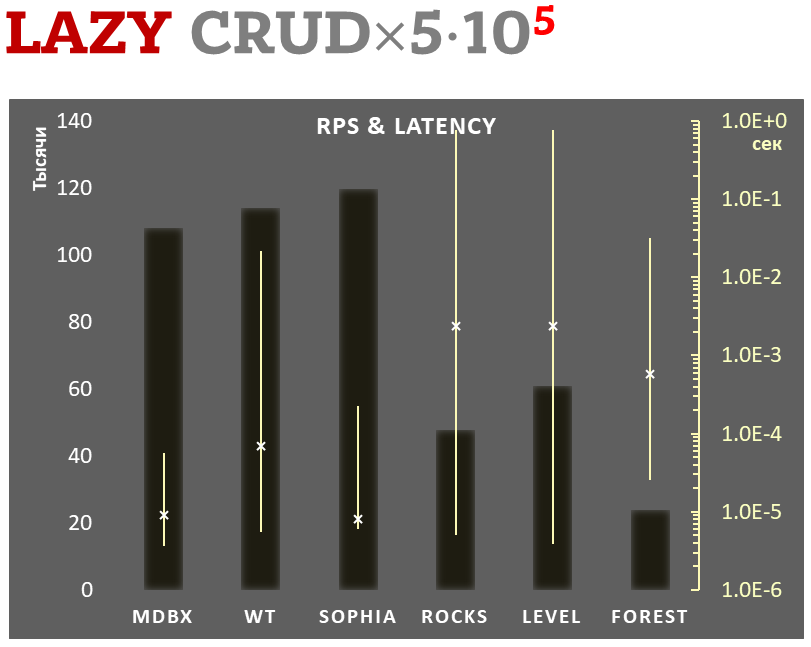
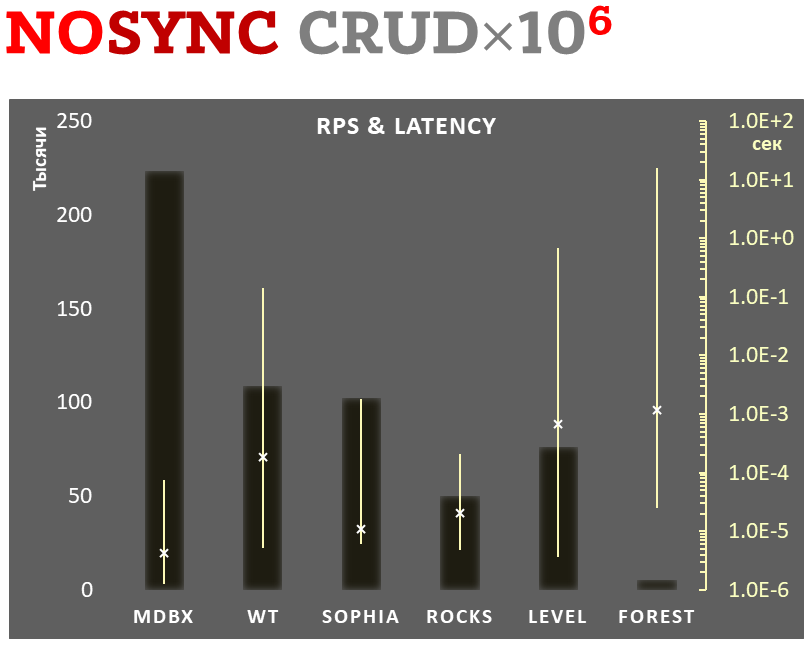
与此同时,mdbx 改进了不少 lmdb 的缺憾,因此 Erigon(下一代以太坊客户端)最近从 LMDB 切换到了 MDBX [^erigon] 。
使用教程
如何运行示例
首先克隆代码库 git clone git@github.com:rmw-lib/mdbx.git --depth=1 && cd mdbx
然后运行 cargo run --example 01 ,就运行了 examples/01.rs
如果是自己的项目,请先运行 cargo add mdbx lazy_static
写和读 : set & get
我们先来看一个简单的例子 examples/01.rs
rust 代码如下 :
use ;
use *;
env_rw!;
mdbx!
运行输出如下 :
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/01.mdb
mdbx version https://github.com/erthink/libmdbx/releases/tag/v0.11.2
test1 get Ok(Some(Bin([6])))
[6]
代码说明
env_rw 定义数据库
代码一开始使用了一个宏 env_rw,这个宏有 4 个参数。
-
数据库环境的变量名
-
返回一个 对象,mdbx:: env:: Config 。
我们使用默认配置,因为
Env实现了From<Into<PathBuf>>,所以数据库路径into()即可,默认配置如下。lazy_static!max_db是最大的数据库个数,最多 32765 个数据库,这个设置可以在每次打开数据库时重设,设置太大会影响性能,按需设置即可。其他参数含义参见 libmdbx 的文档 。
-
数据库读事务宏的名称,默认值为
r -
数据库写事务宏的名称,默认值为
w
其中 3、4 参数可以省略使用默认值。
宏展开
如果想看看宏魔法到底干了什么,可以用 cargo expand --example 01 宏展开,此指令需要先安装 cargo install cargo-expand
展开后的代码截图如下:
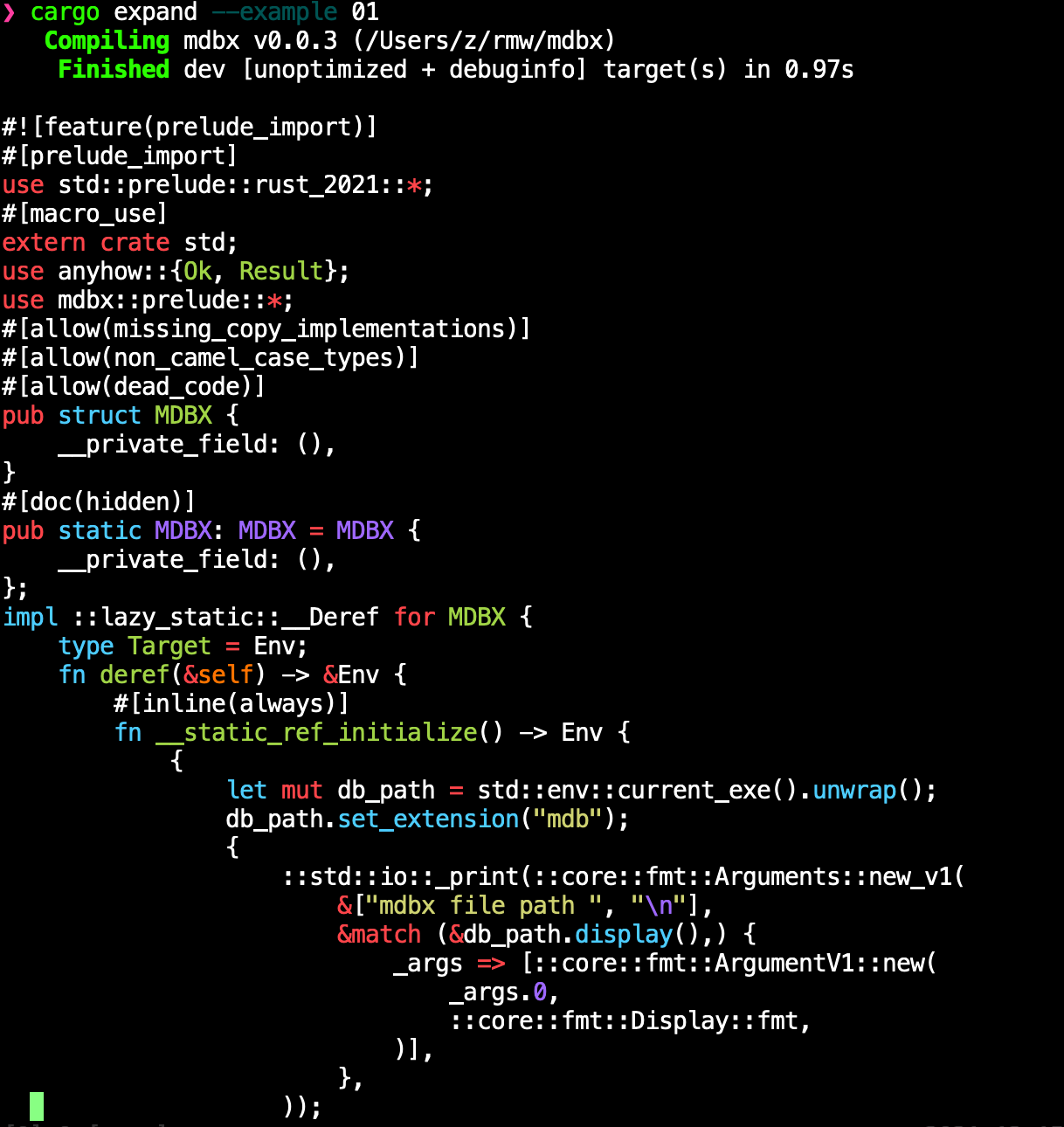
anyhow 和 lazy_static
从展开后的截图,可以看到,使用了 lazy_static 和 anyhow。
anyhow 是 rust 的错误处理库。
lazy_static 是延迟初始化的静态变量。
这两个库很常见,我不赘言。
宏 mdbx!
mdbx!
第一行参数是数据库环境的变量名
第二行是数据库的名称
数据库可有多个,每个一行
线程与事务
上面代码中演示了多线程读写。
值得注意的是,同一线程同一时间只能有一个事务,如果某线程打开了多个事务会程序会崩溃。
事务会在作用域结束时提交。
读写二进制数据
let tx = w!;
let test = tx | Test;
test.set?;
println!;
match test.get?
set 是写,get 是读,任何实现了 AsRef<[u8]> 的对象都可以写入数据库。
get 出来的东西是 Ok(Some(Bin([6]))),可以转为 &[u8]。
第二个例子
我们来看第二个例子 examples/02.rs :
这个例子中,env_rw! 省略了,第三、第四个参数(r, w)。
use ;
use *;
env_rw!;
mdbx!
运行输出如下
mdbx file path /Users/z/rmw/mdbx/target/debug/examples/02.mdb
u16::from_le_bytes(Bin([4, 5])) = 1284
-- loop test1
[2] = [3]
[2, 3] = [4, 5]
[8, 1] = [9]
[9] = [10, 12]
[97, 98, 99] = [48, 49, 50]
[114, 109, 119, 46, 108, 105, 110, 107] = [68, 111, 119, 110, 32, 119, 105, 116, 104, 32, 68, 97, 116, 97, 32, 72, 101, 103, 101, 109, 111, 110, 121]
get after del Ok(None)
-- loop test2
abc = 012
rmw.link = Down with Data Hegemony
-- loop test3
0 = 6
10 = 5
13 = 32
16 = 32
-15 = 6
-12 = 6
-10 = 6
-- loop test4 rev
16 = 3
16 = 2
16 = 1
13 = 32
10 = 5
10 = 0
0 = 6
快捷读写
若只是想简单的读取或写入单行数据,我们可以用宏的语法糖。
读数据
r!(Test1.get [2, 3])
写数据
w!
都一行搞定, 正如 examples/02.rs 写的那样。
数据类型 和 数据库标志
在 examples/02.rs 中,数据库定义是这样的 :
Test2 // 数据库 Test2
key
val
Test3 // 数据库 Test2
key i32
val u64
Test4 // 数据库 Test3
key u64
val u16
flag DUPSORT
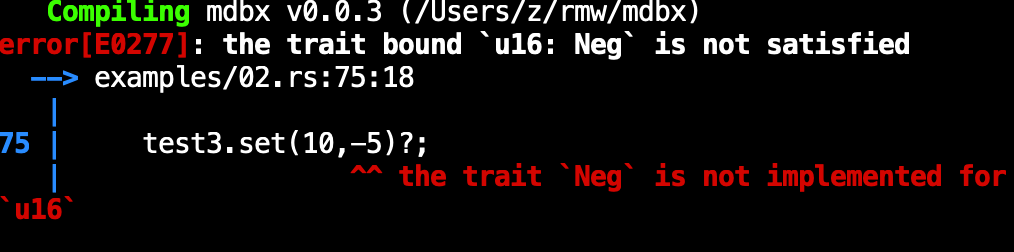
其中 key 和 val 分别定义了键和值的数据类型。
如果试图写入的数据类型和定义的不匹配,会报错,截图如下 :
预置数据类型
遍历
自定义数据类型
一个键对应多个值
删除一个精确匹配的键值对
迭代器
数据库标志
MDBX_REVERSEKEY 对键使用反向字符串比较。(当使用小端编码数字作为键的时候很有用)
MDBX_DUPSORT 使用排序的重复项,即允许一个键有多个值。
MDBX_INTEGERKEY 本机字节顺序的数字键 uint32_t 或 uint64_t。键的大小必须相同,并且在作为参数传递时必须对齐。
MDBX_DUPFIXED 使用 MDBX_DUPSORT 的情况下,数据值的大小必须相同(可以快速统计值的个数)。
MDBX_INTEGERDUP 需使用 MDBX_DUPSORT 和 MDBX_DUPFIXED;值是整数(类似 MDBX_INTEGERKEY)。数据值必须全部具有相同的大小,并且在作为参数传递时必须对齐。
MDBX_REVERSEDUP 使用 MDBX_DUPSORT;对数据值使用反向字符串比较。
MDBX_CREATE 如果不存在,则创建 DB。
MDBX_DB_ACCEDE
打开使用未知标志创建的现有子数据库。 该 MDBX_DB_ACCEDE 标志旨在打开使用未知标志(MDBX_REVERSEKEY、MDBX_DUPSORT、MDBX_INTEGERKEY、MDBX_DUPFIXED、MDBX_INTEGERDUP 和 MDBX_REVERSEDUP)创建的现有子数据库。 在这种情况下,子数据库不会返回 MDBX_INCOMPATIBLE 错误,而是使用创建它的标志打开,然后应用程序可以通过 mdbx_dbi_flags()确定实际标志。
默认自动生成的数据库标志
数据库环境全局设置
数据库最大个数
maxdbs 打开数据的时可以更新原有设置。 一开始可以设置小一点的值,有需要再加大。
https://github.com/erthink/libmdbx#limitations
使用注意
键的长度
- 最小 0,最大≈½页大小(默认 4K 页键最大大小为 2022 字节)。
引用说明
[^erigon]: Erigon(下一代以太坊客户端)最近从 LMDB 切换到了 MDBX。
他们列举了从 LMDB 过渡到 MDBX 的好处:
> Erigon 开始使用 BoltDB 数据库后端,然后增加了对 BadgerDB 的支持,最后完全迁移到 LMDB。在某些时候,我们遇到了稳定性问题,这些问题是由我们对 LMDB 的使用引起的,而这些问题是创造者没有预料到的。从那时起,我们一直在关注一个支持良好的 LMDB 的衍生产品,称为 MDBX,并希望使用他们的稳定性改进,并有可能在未来进行更多的合作。MDBX 的整合已经完成,现在是时候进行更多的测试和记录了。
>
> 从 LMDB 过渡到 MDBX 的好处:
>
> 1. 数据库文件的增长 "空间(geometry)" 工作正常。这一点很重要,尤其是在 Windows 上。在 LMDB 中,人们必须事先指定一次内存映射大小(目前我们默认使用 2Tb),如果数据库文件的增长超过这个限制,就必须重新启动这个过程。在 Windows 上,将内存映射大小设置为 2Tb 会使数据库文件一开始就有 2Tb 大,这不是很方便。在 MDBX 中,内存映射大小是以 2Gb 为单位递增的。这意味着偶尔的重新映射,但会带来更好的用户体验。
>
> 2. MDBX 对事务处理的并发使用有更严格的检查,以及在同一执行线程中的重叠读写事务。这使我们能够发现一些非明显的错误,并使行为更可预测。
> 在超过 5 年的时间里(自从它从 LMDB 中分离出来),MDBX 积累了大量的安全修复和 heisenbug 修复,据我们所知,这些修复仍然存在于 LMDB 中。其中一些是我们在测试过程中发现的,而 MDBX 的维护者也认真对待,并及时进行了修复。
>
> 3. 当涉及到不断修改数据的数据库时,它们会产生相当多的可回收空间(在 LMDB 术语中也被称为 "freelist")。我们不得不给 LMDB 打上补丁,以修复在处理可回收空间时最严重的缺点 [(分析)](https://github.com/ledgerwatch/erigon/wiki/LMDB-freelist-illustrated-guide) 。[MDBX 对可回收空间的有效处理进行了特别的关注,到目前为止,还不需要打补丁。](https://github.com/ledgerwatch/erigon/wiki/LMDB-freelist-illustrated-guide%EF%BC%89%E3%80%82MDBX%E5%AF%B9%E5%8F%AF%E5%9B%9E%E6%94%B6%E7%A9%BA%E9%97%B4%E7%9A%84%E6%9C%89%E6%95%88%E5%A4%84%E7%90%86%E8%BF%9B%E8%A1%8C%E4%BA%86%E7%89%B9%E5%88%AB%E7%9A%84%E5%85%B3%E6%B3%A8%EF%BC%8C%E5%88%B0%E7%9B%AE%E5%89%8D%E4%B8%BA%E6%AD%A2%EF%BC%8C%E8%BF%98%E4%B8%8D%E9%9C%80%E8%A6%81%E6%89%93%E8%A1%A5%E4%B8%81%E3%80%82)
>
> 4. 根据我们的测试,MDBX 在我们的工作负载上表现得稍微好一些。
>
> 5. MDBX 暴露了更多的内部遥测数据 — 更多关于数据库内部发生的指标。而我们在 Grafana 中拥有这些数据 — 以便在应用设计上做出更好的决定。例如,在完全过渡到 MDBX 之后(移除对 LMDB 的支持),我们将实施 "提交半满事务 " 策略,以避免溢出/未溢出的磁盘接触。这将进一步简化我们的代码,而不影响性能。
>
> 6. MDBX 支持 "Exclusive open " 模式--我们将其用于数据库迁移,以防止任何其他读者在数据库迁移过程中访问数据库。
>
> MDBX 支持“ Exclusive open”模式 — 我们使用它进行 DB 迁移,以防止任何其他读取器在 DB 迁移过程中访问数据库。
关于
本项目隶属于 人民网络(rmw.link) 代码计划。
![]()