# Benchmarks
The above benchmark shows the speed boost this gives for 10-NN, but this datastructure is intended (by me) to be used for fast feature matching in images. When matching features in images, they must satisfy the lowe's ratio, which means that the first match must be significantly better than the second match or there may be ambiguity. ~~For that purpose, here are several 2-NN benchmarks for 256-bit binary descriptors:~~ Currently, I only made one benchmark because a performance improvement happened and the existing graphs are no longer representative.

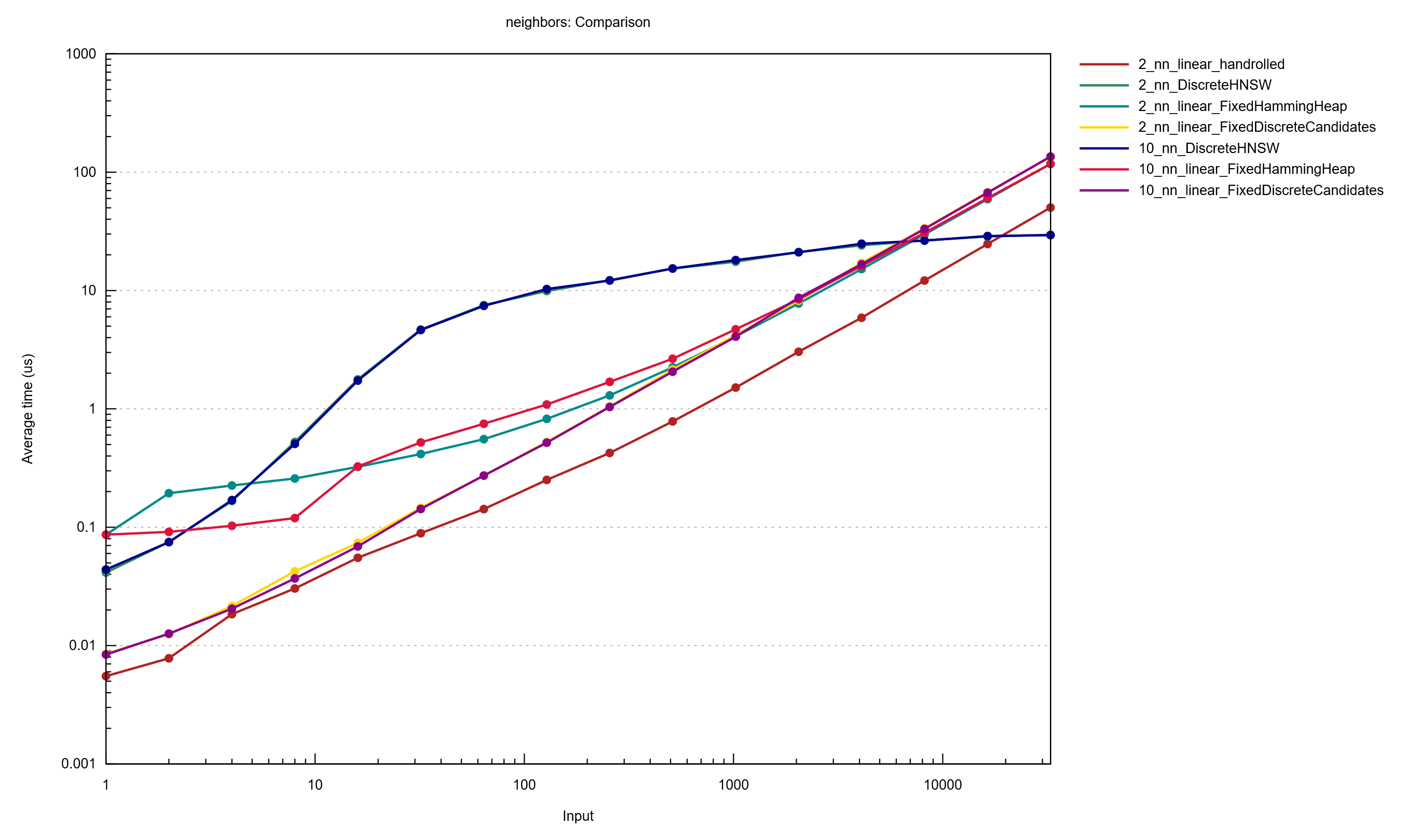
Please note that `M = 24` is not optimal for the above graph at 10000 items. The default `M` on this implementation is `12`, which can be fairly optimal for the 2-NN case.
You can find benchmarks of HNSW with 256-bit binary features vs linear search on 2-NN with `ef` parameter of `24`, `M` parameter of `24` (very high recall), and `efConstruction` set to `400` [here](http://vadixidav.github.io/hnsw/839611966a1550d5cba599c78002ee68311e4c37/report/index.html). This compares it against linear search, which is pretty fast in small datasets. This is not really a valid comparison because it is comparing apples to oranges (a linear search which is perfect with an ANN algorithm that is getting worse at recall). However, this benchmark is useful for profiling the code, so I will share its results here. Please use the recall graphs above as the actual point of comparison.
You can also generate recall graphs. Use the following to see how:
```bash
# Discrete version (binary descriptors)
cargo run --release --example recall_discrete -- --help
# Non-discrete version (floating descriptors)
cargo run --release --example recall -- --help
```
It is highly recommended to use real-world data. If you don't want to use random data, please use the `generate.py` script like so:
```bash
# AKAZE binary descriptors
python3 scripts/generate.py akaze 2011_09_29/2011_09_29_drive_0071_extract/image_00/data/*.png > data/akaze
# KAZE floating point descriptors
python3 scripts/generate.py kaze 2011_09_29/2011_09_29_drive_0071_extract/image_00/data/*.png > data/kaze
```
This code ran againt the Kitti dataset `2011_09_29_drive_0071`. You can find that [here](http://www.cvlibs.net/datasets/kitti/raw_data.php). Download "[unsynced+unrectified data]". It is a large (4.1 GB) download, so it may take some time.
You can still run the above generation against any dataset you would like if you would like to test its performance on said dataset.
This crate may take a while to compile due to the use of `typenum` and `generic-array`. If you dislike this, consider contributing to some issues labeled [A-const-generics](https://github.com/rust-lang/rust/labels/A-const-generics) in Rust to help push along the const generics support in the compiler. The `recall_discrete` generator is especially time-consuming to build.