Expand description
§Bigoish: Test the empirical computational complexity of Rust algorithms
Created by humans!
Your functions or datastructure methods implement an algorithm; how do you know if they’re scaling as expected? For example, imagine you’ve implemented a new sorting algorithm. Decent sorting is typically O(nlogn), but how about your implementation? Maybe there’s a bug somewhere that makes it worse.
With bigoish, pronounced “big-o-ish”, you can write tests that assert that a particular function has a particular empirical computational complexity.
More accurately, you can assert that an expected complexity model you provide is empirically the best fit for measured runtime, when compared to the fits of a specific set of common complexity models.
Real big-O, in contrast, is a mathematically-proven upper bound.
Here’s an example, asserting that Rust’s built-in sort() fits n*log(n) best:
use bigoish::{N, Log, assert_best_fit, growing_inputs};
// The function whose complexity we want to assert.
fn sort(mut v: Vec<i64>) -> Vec<i64> {
v.sort();
v
}
// Creates a test input of a particular size for `sort()`.
fn make_vec(n: usize) -> Vec<i64> {
// Random number generation library:
use fastrand;
std::iter::repeat_with(|| fastrand::i64(..)).take(n).collect()
}
// Assert that that n*log(n) is the complexity model that fits `sort()` best.
assert_best_fit(
// The expected best-fitting computational complexity model:
N * Log(N),
// The function being tested:
sort,
// Pairs of (input length, input); the inputs will be passed to `sort()`.
[
(10, make_vec(10)), (100, make_vec(100)), (1000, make_vec(1000)),
(10_000, make_vec(10_000)), (100_000, make_vec(100_000))
]
);
// You can use `growing_inputs()` to generate input pairs more easily.
assert_best_fit(
N * Log(N),
sort,
// Starting with input size 200, generate 25 increasingly larger inputs
// using `make_vec()`.
growing_inputs(200, make_vec, 25),
);If you were to erroneously assert that sort() uses model N:
assert_best_fit(N, sort, growing_inputs(10, make_vec, 25));You would then get a panic that looks like this:
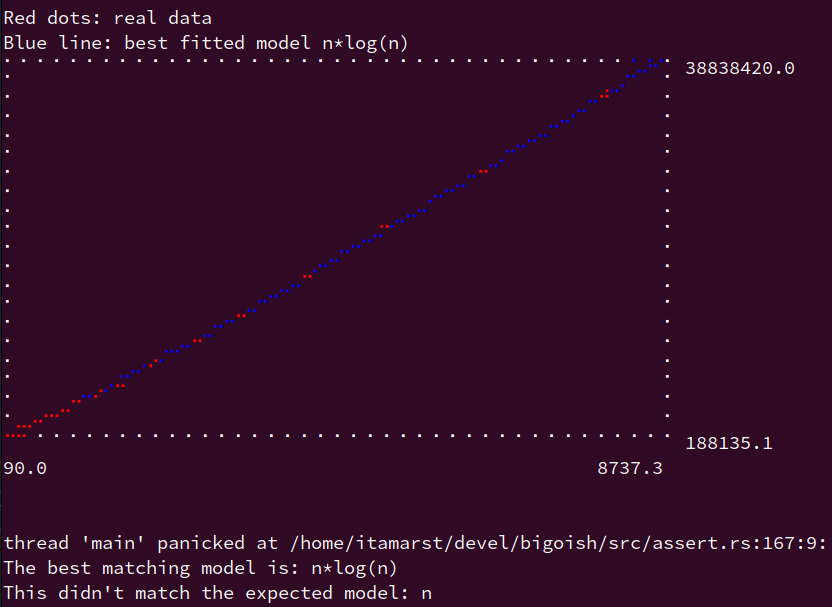
§Improving your chances of a correct fit
Sometimes assert_best_fit will misidentify your function’s likely complexity, claiming that, for example, n*log(n) is the best fit for your function despite it clearly being linear.
Or, it may fail intermittently.
To reduce the chances of this happening, you should:
- Use a sufficient number of inputs. Using 20 inputs is better than using 4 inputs.
- Make sure your inputs span a number of orders of magnitude.
For example, if your function takes a
Vec, testing with vectors of length 10, 100, 1000, and 10_000 is better than lengths of 10, 11, 12, and 13. Thegrowing_inputs()function is a useful way to generate a sequence of increasingly bigger inputs. - Make sure the minimal size of your inputs is large enough. Tiny inputs may have too much noise when the function’s runtime is measured.
§Differences between release and test profiles
Typically cargo test runs with the “test” profile, whereas released code runs with the “release” profile.
The latter drops debug assertions, and compiles with optimizations.
As a result, if you’re using assert_best_fit in a #[test], by default when you run cargo test you’ll be asserting on code that is compiled differently than in released code.
Most of the time, this doesn’t matter; the “test” profile will result in slower code, but not in a different computational complexity.
Sometimes, however, “release” profile will allow the compiler to optimize your code into something much more scalable; perhaps a loop can be optimized into a constant-time operation.
In that case, you’ll want to run assert_best_fit under the “release” profile in order to assert the correct complexity model.
You can make your test only run if debug assertions are disabled:
#[cfg(not(debug_assertions))]
#[test]
fn complexity_of_sort() {
assert_best_fit(
N * Log(N),
sort,
[
(1000, make_vec(1000)),
(10_000, make_vec(10_000)),
(100_000, make_vec(100_000))
]
)
}And then run tests with the “release” profile:
cargo test --releaseCaution: Compiling with the release profile doesn’t interact will with the time-based profiling, increasing the chances of flaky or incorrect checks due to noise. Since time-based profiling is going to be pretty common (any non-Linux environment, many cloud Linux environments including GitHub Action), you may wish to avoid this until support for a better alternative to CPU instructions is implemented.
§Cargo features
The following features are enabled by default:
plots: Generate a plot in the terminal if the assertion fails. You can also disable this at runtime for accessibility reasons, see below; the goal of the feature is to reduce dependencies.cpu-instructions: Whether to try to measure CPU instructions; currently only has an effect on Linux.
§Accessibility
If assert_best_fit panics and you’re using a terminal, it will generate a graph showing how well the best fitting model matches your inputs and their measured runtime.
That way you can visually see if the proposed alternative model makes sense or not.
If you’re using a screen reader, you can disable this behavior by setting either NO_COLORS or TERM=dumb environment variables.
Both, especially the latter, will likely impact the behavior of other programs.
§How it works
assert_best_fit takes an expected complexity model, a single-threaded function, and inputs (or rather, input sizes plus values).
assert_best_fit then tries to fit pairs of (input size, measured runtime of function(input)) to the given model, as well as to additional models: constant, n, n², n³, √n, log(n), nlog(n), log(log(n)).
If the best-fitting model is the one you asserted, all is well; if not, assert_best_fit panics.
You can construct new models from the existing implementations of Model, or create your own.
How runtime is measured depends on your operating system and environment:
- On Windows and macOS, the measurement uses CPU usage time on the current thread.
- On Linux, an attempt will be made to use the CPU instruction count for the current thread. However, this doesn’t work in all environments, for example it doesn’t work on GitHub Actions. If CPU instruction counts are unavailable, CPU usage time will be used instead.
- If you set an environment variable
BIGOISH_TIME_ONLY=1, CPU usage time will be used regardless.
Notice that in all cases time spent sleeping or otherwise waiting shouldn’t be counted, though you probably shouldn’t do that in your code in the first place.
§Changelog
§0.1.4
- Moved image out of README and docs, shrinking the package a bit.
§0.1.3
- Notify users about cases where complexity grows meaningfully faster than the worst-case known model, so as to not underestimate empirical complexity.
- More robust measurements.
- Some functionality can now be turned off with Cargo features.
- Added features to allow disabling some optional functionality.
§0.1.2
- Fucked up the release process so 0.1.2 never happened.
§0.1.1
- Added
assert_best_fit_vs_modelsAPI.
§0.1.0
- Initial release.
§Credits
This crate is inspired by the Python library bigO, which in turn is based on Measuring Empirical Computational Complexity by Goldsmith et al.
Structs§
- Constant
- Constant runtime model, equivalent to O(1).
- Known
Models - A set of
Models to check against withassert_best_fit_vs_models. - Log
- Logarithm of another model, e.g.
Log(N)is equivalent to O(log(n)). - Multiplied
Models - The result of multiplying two
Models, e.g.N * Log(N)is equivalent to O(n*log(n)). - Pow
- Power model with fixed exponent, e.g.
Pow(4.)is equivalent to O(n⁴). - Sqrt
- Square root of another model, e.g.
Sqrt(N)is equivalent to O(√n).
Constants§
- N
- A linear model, equivalent to O(n).
- N2
- A quadratic model, equivalent to O(n²).
- N3
- A cubic model, equivalent to O(n³).
Traits§
- Model
- A model of computational complexity.
Functions§
- assert_
best_ fit - Assert the given computational complexity model is the best fit for the given function’s scalability, compared against a reasonable default set of
Models. - assert_
best_ fit_ vs_ models - Like
assert_best_fit, but allows you to override the set of known models to compare against. - growing_
inputs - Create a series of size/input pairs suitable for
assert_best_fit.