
Scholar
A supervised machine learning library for Rust.
If you wish to use Scholar in your project, simply add the following to your Cargo.toml dependencies...
= "0.1"
... then read on to learn about the library's functionality and usage. Note that the following assumes some level of knowledge regarding data science and machine learning.
Datasets
Datasets are objects used to store the data that you want your ML model to learn. They hold a vector of Rows, which are essentially just a tuple of inputs matched to their expected output. You can construct a dataset either directly or from a CSV file:
// Constructs a dataset directly.
// Note that the 'inputs' and 'outputs' are both vectors, even though
// the latter has just one element
let data = vec!;
let dataset = from;
// Constructs a dataset from a CSV file.
// The second argument indicates that the file doesn't have headers,
// and the third specifies how many columns of the file are inputs
let dataset = from_csv?;
You can split a Dataset into two with the split method. This is useful for separating it into training and testing segments:
// Randomly allocates 75% of the dataset to 'training_data',
// and the rest to 'testing_data'
let = dataset.split;
Neural networks
Currently, the library only has functionality for simple neural networks. You can create one like this:
use ;
let mut brain: = new;
You must give the network a type annotation so that it knows which activation function to use. You can create your own activations (something that is covered in this section), or you can simply use the in-built sigmoid.
The argument passed to NeuralNet::new is a slice containing the number of nodes (or neurons) that each layer of the network should have. The code above would produce a network like this:
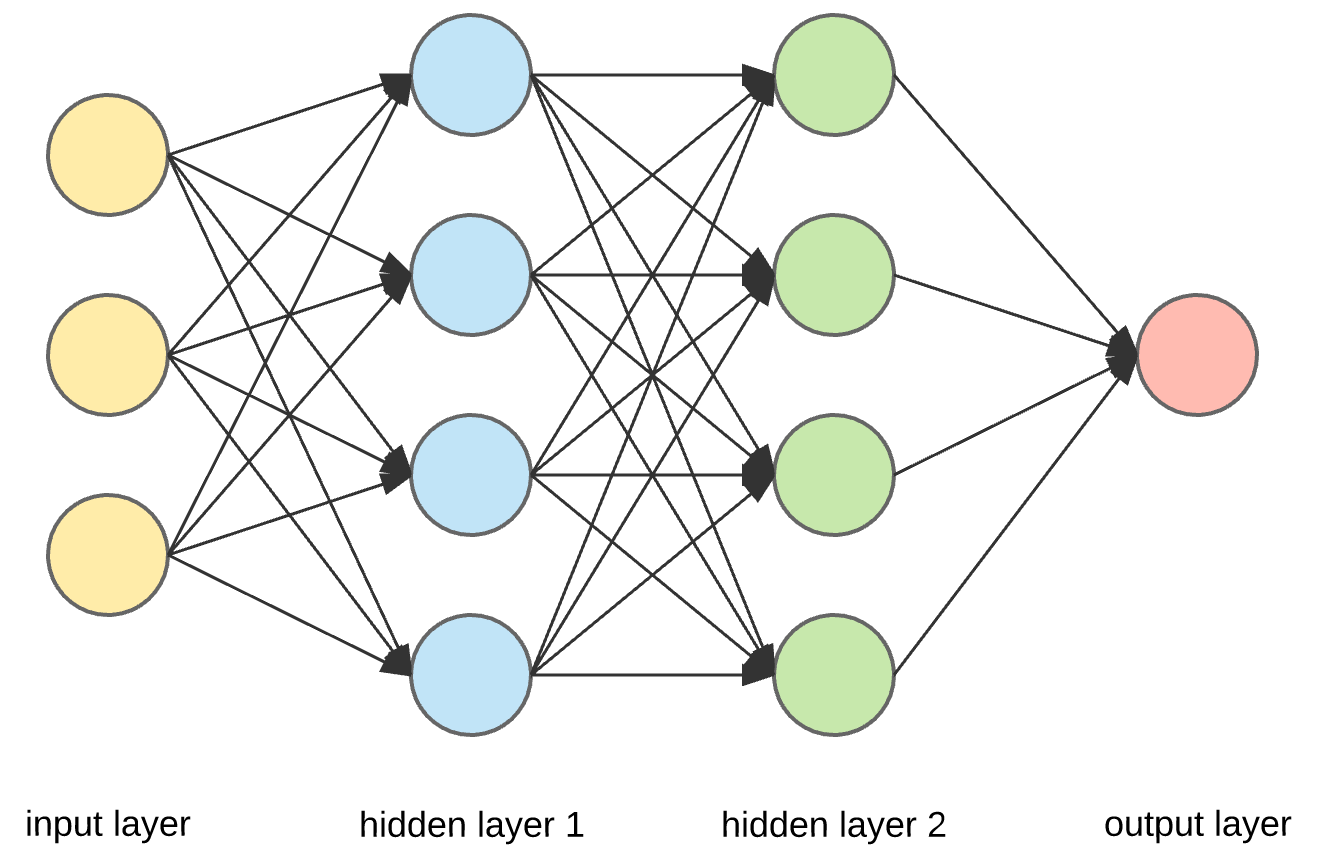
Training and testing
Training and testing a neural network is as easy as it is to create one: just use the train and test methods, respectively:
let mut brain: = new;
// Trains the network by iterating over the entire dataset 25,000 times.
// The last parameter (the 'learning rate') dictates how quickly the network
// 'adapts to the dataset'
brain.train;
let average_cost = brain.test;
println!;
Saving/loading
It's also very simple to save/load networks to/from files.
let mut brain: = new;
brain.train;
// Note that the file doesn't have to use the '.network' extension; you can
// actually choose anything you wish!
brain.save?;
// When loading from a file, you will need to create a new network (or
// shadow an existing one, as is done here)
let mut brain: = from_file?;
Creating custom activations
In order to create a custom activation for a network, you will need to implement the Activation trait, which requires you to fill in both the regular activation function and the derivative of that function. The code below shows how to implement a simple ReLU activation:
use ;
// The activation must be serializable and deserializable
// so that the network can be saved/loaded to/from files
;
A small quirk with this system appears when an activation's derivative references its regular function, such as in the case with sigmoid (σ). The real derivative of σ(x) is:
σ(x) * (1 - σ(x))
When implementing this in code for a neural network, however, we can simply remove these 'references'. This is because the activation's regular function will have always been applied to the input of its derivative function, no matter the circumstances. The derivative of sigmoid thus becomes:
x * (1 - x)
which matches what the real implementation looks like:
Keep this in mind if you plan on building custom activations.
Referencing examples/docs
If at any point you are stuck using this library, be sure to reference the examples (in the examples folder of this repository) or the documentation (at https://docs.rs/scholar/).