
Please check the build logs for more information.
See Builds for ideas on how to fix a failed build, or Metadata for how to configure docs.rs builds.
If you believe this is docs.rs' fault, open an issue.
HyperionDb
[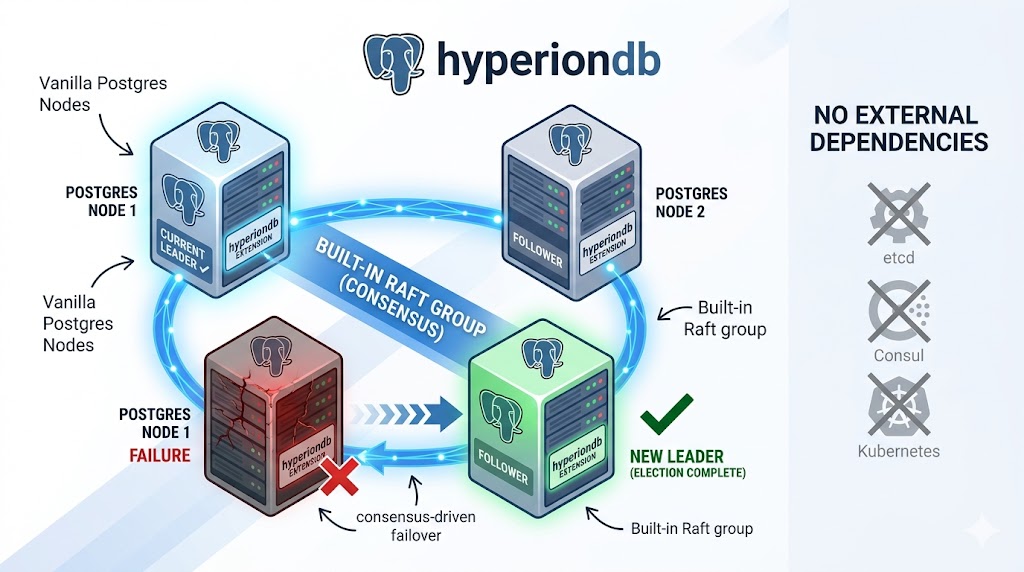
A PostgreSQL extension that gives a small cluster of vanilla Postgres nodes automatic, consensus-driven failover — full-cluster replication (tables, roles, DDL, everything) with a built-in Raft group and no external dependencies: no etcd, no Consul, no Kubernetes.
Replaces Patroni, CloudNativePG, pgActive and many more.
One job: keep a single leader elected and the data byte-identical across N nodes, and fail over automatically when the leader dies. Do that one job well.
Status: in production
The one idea
Don't reinvent replication. Postgres already ships physical (WAL) streaming
replication, which copies everything byte-for-byte — heap, indexes, and the
shared catalog pg_authid (i.e. roles/users and their SCRAM verifiers).
That is exactly why physical replicas have the same roles as the primary, while
logical replication / active-active (pgactive) do not.
pg_replica adds the only piece Postgres itself lacks: automatic leader
election and failover, using an embedded Raft quorum instead of an external
DCS.
| Plane | Who does it |
|---|---|
| Data (tables, indexes, roles, DDL) | Postgres streaming replication — untouched, battle-tested |
| Leadership & failover | Embedded Raft, running inside a Postgres background worker |
| Process lifecycle (start/restart Postgres) | Your existing supervisor — systemd or Docker restart policy |
Result: roles, DDL, and data stay consistent on every node, and a dead primary is replaced in seconds — with no human, no etcd, no Kubernetes.
Features
- Automatic, consensus-driven failover — an embedded Raft quorum keeps a single leader elected and promotes a new primary in seconds when it dies. No etcd, no Consul, no Kubernetes, no external DCS.
- Full-cluster fidelity, for free — tables, indexes, roles + SCRAM verifiers, GRANTs, DDL, and extensions all replicate byte-for-byte over Postgres physical (WAL) streaming replication. Standbys are exact copies, not logical subsets.
- Safe by default — quorum-gated promotion fences the old primary, picks the highest-LSN survivor (no acked-write loss), and self-demotes a minority or network-partitioned primary read-only (no split-brain).
- Deadman watchdog — a control plane that is alive but hung is fenced, not trusted.
- Automatic re-join — a deposed primary
pg_rewind-rejoins as a standby; if its WAL is already gone, it falls back to a fullpg_basebackupre-clone. - Zero committed-transaction loss (opt-in) — quorum-sync ties the Postgres sync quorum (
synchronous_standby_names) to the Raft consensus quorum, so an acked write is always present on the node that gets promoted. - Crash-safe consensus storage — the Raft log, vote, and state machine are persisted with atomic write +
fsyncof both the file data and the containing directory, so an entry acknowledged as durable survives power loss. - Bounded on-disk footprint — the Raft log is compacted via snapshotting; it does not grow without limit.
- Operable from SQL —
SELECT pg_replica.status();,pg_replica.failover(), and friends. No sidecar agent or CLI required. - Client follows the failover — a multi-host libpq / Node client (
target_session_attrs=read-write) re-resolves the new primary on reconnect; the extension only publishes who the primary is. - Lightweight — one
.soplus Postgres: single-digit-MB private memory, sub-percent idle CPU, ~5 s to a writable new primary.
End-user install
|
# enable the extension
CREATE EXTENSION IF NOT EXISTS pg_replica;
CREATE ROLE replicator WITH REPLICATION LOGIN PASSWORD '<pass>'; // *same* password used for main user
Performance (highly subjective numbers for 0.1.0)
pgbench, 8 clients / 4 jobs, single-row INSERT on the primary, 10 s, async mode
Memory
- 8 MB RSS
- 2 MB PSS
- 0.8 MB private
CPU
- 0.38% idle
Throughput
- 2494 tps
- 3.2 ms avg latency
- 17.6k rows
Failover latency
- 5 s to writable new primary
Test
The whole suite runs against a real 3-node cluster in Docker — the only prerequisite is Docker (Desktop on Windows/macOS, or Engine on Linux). No local Rust, pgrx, Postgres, or WSL is required; the extension and the test clients are built inside the images.
Run the whole test suite
One command builds the node + runner images and runs every test, bringing up a fresh 3-node cluster per test and tearing it down afterward:
Note. It's a long run (> 20 min).
# Windows (PowerShell)
./scripts/test.ps1 # build, then run all tests + summary
./scripts/test.ps1 -NoBuild # skip the image rebuild
# Linux / macOS / CI
How it works: docker/docker-compose.test.yml runs the 3 nodes (built from
docker/Dockerfile with TEST_TOOLS=1, which adds iptables, libfaketime,
jq, procps) plus a slim runner container that holds the test scripts, the
Rust probe/chaos-writer/model binaries, and the Docker CLI. The runner drives the
cluster through scripts/lib.sh primitives: docker kill/start/restart for node
failure, docker exec kill -STOP for control-plane hangs, docker pause for a
whole-primary freeze, in-container iptables for raft partitions, and
libfaketime for clock skew.
Coverage (scripts/test-*.sh, each spins a real 3-node cluster):
| Test | Proves |
|---|---|
test-model |
formal model check (stateright, exhaustive, N=3 and N=5): (1) durability — the sync-quorum math (ack = majority) loses no acked transaction across every reachable crash/failover interleaving; (2) split-brain — a resurrected stale-term primary can never commit a conflicting write (a commit needs a majority still at the leader's term). Both have negative controls that produce counterexamples |
test-m3-lsn |
failover promotes the highest-LSN survivor (no data loss) |
test-m4-fence |
minority primary self-demotes read-only (no split-brain) |
test-m4-watchdog |
a hung control plane is fenced by the deadman watchdog |
test-m4-partition |
a network-partitioned (but running) primary self-demotes |
test-m5-rejoin |
deposed primary pg_rewind-rejoins as a standby |
test-m5-walgone |
WAL gone → automatic pg_basebackup re-clone |
test-compaction |
Raft log stays bounded via snapshotting |
test-m6-routing |
a multi-host client follows the failover with only a reconnect |
test-m7-sync |
quorum-sync = zero committed-transaction loss on failover |
test-quorum-consistency |
the Postgres sync quorum (synchronous_standby_names) and the Raft consensus quorum name the same nodes, and a write confirmed by one standby is promoted onto that standby — no two-quorum drift on failover |
test-perf |
supervisor memory (single-digit MB private overhead), idle CPU, write throughput (pgbench), and failover latency |
test-chaos |
Jepsen-style: continuous writer under partitions / freeze / kill / clock-skew / slow-disk / rolling-restart — 0 split-brain, converges, zero-loss for clean failovers |
Goals / non-goals
Goals
- Automatic failover on a 3- or 5-node cluster (Raft majority quorum).
- Full-cluster fidelity: roles, GRANTs, DDL, extensions, data — all replicated (free, via physical replication).
- Zero external coordination services (Raft is embedded).
- Lightweight: one
.soextension + Postgres; no JVM, no Go control plane, no k8s. - Safe by default: quorum-gated, fences the old primary, picks the most-advanced
replica, rejoins the loser with
pg_rewind. - Operable from SQL:
SELECT pg_replica.status();,pg_replica.failover(), etc.
Non-goals
- Sharding / horizontal write scale-out → that is Citus, a different axis.
- Connection pooling / proxy → recommend HAProxy or libpq multi-host
(
target_session_attrs=read-write). pg_replica only publishes who the primary is. - Backups / PITR → recommend pgBackRest or wal-g.
- Logical / multi-master replication → out of scope by design.
Positioning (honest prior art)
| Tool | Consensus | External deps | Form factor |
|---|---|---|---|
| CloudNativePG | k8s control plane | Kubernetes required | operator |
| Patroni | etcd/Consul/k8s — or pysyncobj Raft mode |
DCS (or its raft lib) | Python agent |
| pg_auto_failover | single monitor node (not quorum) | a monitor Postgres | C ext + agent |
| Stolon | external store (etcd/consul) | DCS | Go agents |
| repmgr | none (manual/assisted) | — | C ext + CLI |
| pg_replica (this) | embedded Raft quorum | none | Postgres extension |
The niche: embedded quorum (unlike pg_auto_failover's single monitor), no
external DCS (unlike Patroni-etcd / Stolon), no Kubernetes (unlike CNPG),
shipped as a plain Postgres extension. Closest existing thing is Patroni's
raft DCS mode — pg_replica aims to be that idea, but native, in-process, and Rust-light.
Gotchas (sic!)
- If a standby ever runs a different glibc than the primary that built the btree indexes, the standby's text/varchar indexes are silently mis-ordered. The instant extension promotes that standby, index-using queries return missing/duplicate rows with nothing in the logs. Extensions's entire job is safe promotion; a glibc skew turns a clean failover into silent corruption
- Extension rusn 100 ms tick, 250 ms heartbeats, 1000–2000 ms election window. A bad multi-hundred-ms (or >1 s) stall of THP on the primary's host can delay heartbeats/gossip enough that standbys mark it unhealthy and start an election - a spurious failover of a healthy primary.
- Deadpool's RecyclingMethod::Fast doesn't re-route an existing connection — so a connection that fell back to the primary during a standby outage stays pinned there until it's recycled out of the pool. That's the same stickiness libpq's prefer-standby has; under normal operation (standbys present) every new connection lands on a standby.
Docs
- docs/ARCHITECTURE.md — components, failover flow, fencing, the hard problems.
- docs/DECISIONS.md — the load-bearing design choices and why.
- docs/DURABILITY.md — zero-loss configuration, failure modes, what backups still cover.
- docs/TODO.md — phased milestones
- docs/CLIENT_TODO.md — phased milestones for nodejs addon
- docs/DOCKER_CONFIG.md - Docker config (ParadeDb as example)